Python 3 データ分析試験の勉強方法
- fukutaku
- 2022年10月30日
認定テキストは下記です。
1章から5章まであります。
こちらを読み込めば大丈夫なのですが
完全に読み込むのは初学者にはきついです。
受験した記憶から出題された問題をまとめてみました!
※問題を持ち帰ることはできないので私の記憶の限り記載しています。
※過去問は配布されておりません。
※5章は試験範囲外ですので省略しています。
もくじ
- 第1章 データ分析エンジニアの役割
- 第2章 Pythonと環境
- 第3章 数学の基礎
- 第4章 ライブラリによる分析の実践
第1章 データ分析エンジニアの役割
1-1データ分析の世界
データ分析は幅広い分野で行われています。
例えば工場システムから出力される機器の温度変化や回転数などのデータを基に異常の兆候を事前に発見することが可能になりました。
データ分析ではPythonがデフォルトです。
Pythonはコンパイル不要なオープンソースのスクリプト言語です。
Pythonには多くの標準ライブラリがそろっていますが、外部パッケージも必要です。
有名なものにはJupyterNotebook、NumPy、pandas、Matplotlib、SciPy、scikitlearnがあります。
データサイエンティストは数学、情報工学、対象分野の専門知識が必要です。
対してデータ分析エンジニアでは最低限持つべき知識は以下となります。
| 必要技術 | 詳細 | 対応パッケージ、ライブラリ |
| データ入手、加工 | データを入手して、加工する技術 | Numpy、pandas |
| データの可視化 | グラフ等で分かり易くする | Matplotlib、pandas |
| プログラミング | Pythonのスキル | Python |
| インフラレイヤー | サーバ構築のスキル |
1-2機械学習の位置づけと流れ
機械学習は大量のデータから一定の法則性を見つけてそれを数式化します。
モデルといいます。
モデルはデータとアルゴリズムにて作成します。
このモデルに入力データ以外のデータ(未知データ)を入力して予測を行います。
機械学習なしに予測することも可能です。
1つ目はルールベースです。
単純に明日の天気が晴れなら売上予測が10万以上、雨なら3万未満、曇りなら3万~10万未満等の予測を立てます。
判別材料となるのは晴れ、曇り、雨の3パターンだけになりますのでルール化は可能です。
別の言い方をすればプログラミング可能です。
ですがルールが複雑になればなるほどプログラミングが不可能になります。
2つ目は統計です。
統計データから未知のデータを予測します。
ただ機械学習アルゴリズムは統計的手法のものも多いため明確に分類することはできません。
機械学習については以下の3パターンに分類できます。
- 教師あり学習
- 教師なし学習
- 強化学習
教師あり学習
学習に利用する訓練データに正解となるラベルデータが存在する場合に用いられる方式です。
例えば手書き文字を認識するAIを開発したいとします。
以下のように手書きの訓練データに正解が付与されている場合に教師あり学習が用いられます。
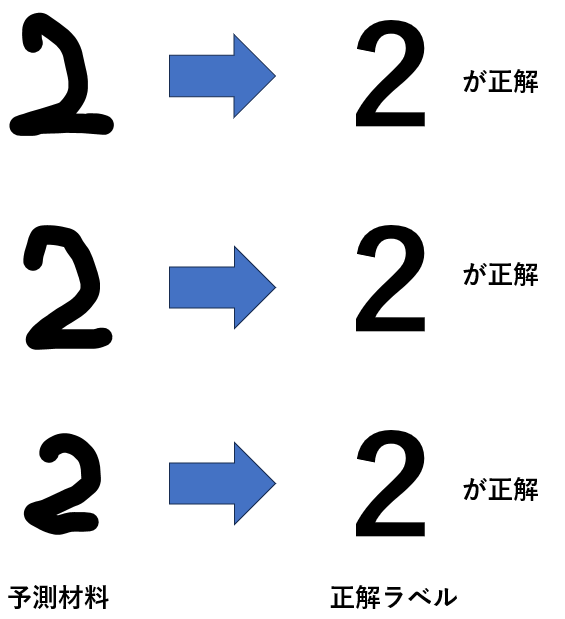
教師あり学習では回帰と分類の2種類があります。
まずは回帰です。
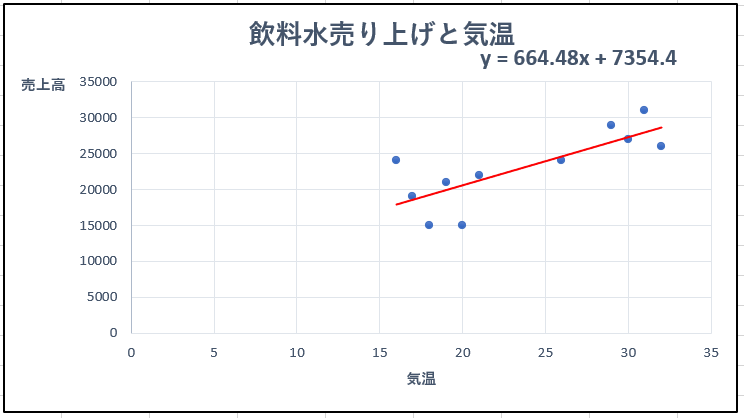
例えばあるコンビニで日の最高気温と飲料水の売り上げに相関性があるとします。
以下グラフ化します。
気温が上がると売上高も上がるという相関があります。
この関係性を\(y = 664.48x + 7354.4\)という数式(モデル)で表現できます。
※アルゴリズムは最小二乗法になります。
このモデルを用いて明日の売上高を予想してみましょう。
明日は27度になるという予報でした。以下のモデル\(x\)に\(27\)を代入します。
\(y = 664.48x + 7354.4\)から2万5295円と予想できます。
\(y\)つまり売上高を目的変数、\(x\)つまり気温を説明変数(特徴量)といいます。
現場ではこうした予想から仕入れ量を調整したりできます。
このように目的変数が連続値となるものを回帰といいます。
これに対して分類は目的変数がカテゴライズされているデータとなります。
例えばある顧客がその商品買うか買わないかを予測したいとします。
買うか買わないかが目的変数になるので\(0\)もしくは\(1\)を出力すればいいのです。
買うか買わないかを\(y\)(目的変数)として\(0\)か\(1\)が入ります。
説明変数は\(x1、x2\)でそれぞれに重み\(w1、w2\)がかかります。
\(y=b+x1w1+x2w2\)
\(y ≦ 0\) なら \(0\) を出力(買わない)
\(y > 0\) なら \(1\) を出力(買う)
このようなモデルを分類といいます。
分類アルゴリズムは下記のものが有名です。
- サポートベクタマシン(外れ値検出にも用いられる)
- 決定木
- ランダムフォレスト
教師なし学習
対して正解ラベルのない学習を教師なし学習といいます。
正解ラベルのない、つまり目的変数がないということです。
やや疑問かもしれませんが、それでもグループ分けをする手法になります。
代表的なものにクラスタリングがあります。
詳細アルゴリズムはk-meansや階層的クラスタリングがあります。
ここではイメージだけ掴んで頂ければ幸いです。
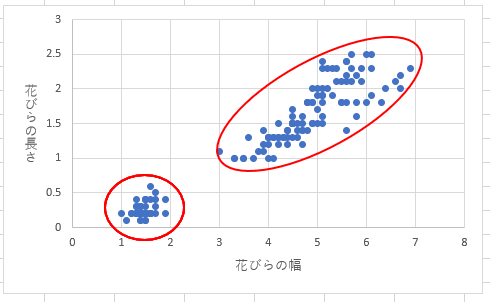
アヤメという花を例に解説致します。

アヤメの花びらの長さをy軸、と幅をx軸として散布図を作ります。
すると大きく2つのグループに感覚的に分けれそうです。
つまりこの結果を用いて(モデルを用いて)未知のデータの花びら幅と長さを説明変数として
どちらのグループに属するかを予測するわけです。
強化学習
現在の状況をもとに取るべき行動を決定することを学習する仕組みです。
人間のプロに勝ったAlphaGoには強化学習が使われています。
教師あり学習と似てはいるのですが、明確な正解は与えられていません。
機械学習の処理の手順
正しい手順を選択せよという問題がありました。
処理の流れを記憶しておきましょう。
- データ入手
- データ加工
- データ可視化
- アルゴリズム選択
- 学習プロセス
- 精度評価
- 試験運用
- 結果利用
・データ入手、データ加工
データがなければ何も始まりません。
手に入れたデータはNumPy、pandasといったパッケージにて整え、欠損値対応をします。
・データ可視化
データを表やグラフで可視化します。
Matplotlibが活用されます。
・アルゴリズム選択
目的やデータに沿ったアルゴリズムを選択します。
この段階ではscikit-learnが活用されます。
・学習プロセス
この段階でもscikit-learnを活用し、学習を行います。
・精度評価
学習したモデルを用いて予測を行います。
この時は学習に使ったデータではなく、検証用の別データを用います。
単純に正解率だけで結論を出してはいけません。
この段階でもscikit-learnが活用されます。
・試験運用
この段階では結果のわからない未知のデータでの実行が必要になります。
結果が思わしない場合は、各プロセスを見直し、再実行します。
これらの繰り返しがより良い結果を作っていくことになります。
・結果利用
実業務に利用できるくらいの制度になれば、未知データを入力して予測するシステムを構築することができます。
1-3データ分析に使う主なパッケージ(ライブラリ)
※書籍によってパッケージとライブラリの言葉の定義が異なります。
あまり気にしなくてよいでしょう。
NumPy
Numpyの基礎的なところは下記で解説しています。
数値計算を扱うパッケージになります。
pandas
pandasの基礎的なところは下記で解説しています。
表データを加工するパッケージになります。
Matplotlib
Pythonで主に2次元のグラフを描画するためのライブラリになります。
このライブラリについての問題もそこそこあったかと思います。
matplotlib.pyplot をインポートします。
import matplotlib.pyplot as plt
それからグラフ化したいデータを用意します。
ndarray形式で作成します。
import numpy as np
y = np.random.rand(5)
y = y*10
print(y)
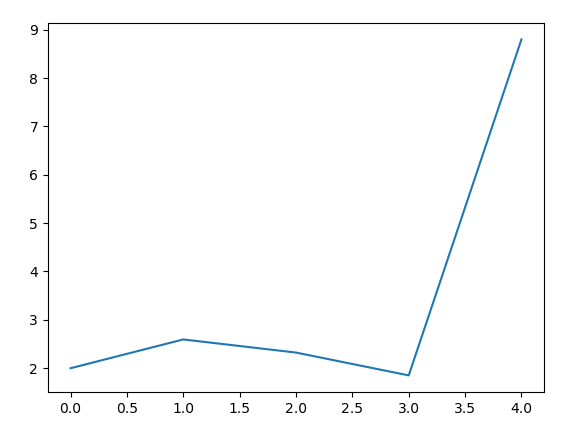
以下のようにランダムなデータが出来上がりました。

それではこのデータをグラフ化します。
plt.plot(y)
plt.show()
x軸についてのデータも任意の値を設定することができます。
x = np.array([1,2,3,4,5])
plt.plot(x,y)
plt.show()
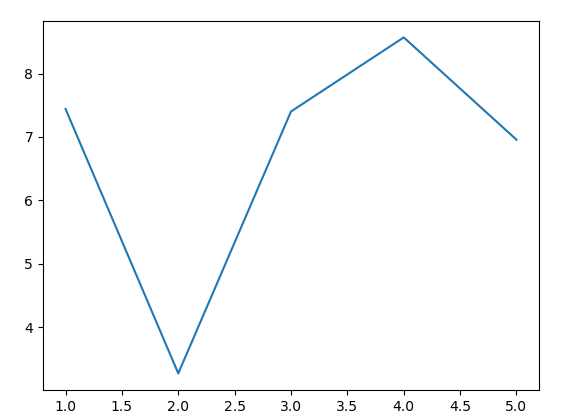
※y軸の値はランダム関数を利用していますので値は毎回変化します。
scikit-learn
多くのサンプルデータを持っており、様々なアルゴリズムが実装されています。
詳細は後述します。
SciPy
NumPyと同様に数値計算を行います。
SciPyを構成する要素のひとつがNumPyです。
第2章 Pythonと環境
2-1実行環境構築
まずPython公式サイトからダウンロードします。
python.exe は Python をインストールしたディレクトリに保存されています。
そのディレクトリまでのPATHを設定することで、フルパスで指定する必要がなくなります。
インストール中に[Add Python to Path]という項目にチェックを入れることでPATHが設定されます。
コマンドプロンプトでpython -Vと入力して以下のようにバージョンが表示されれば
無事にパスが設定されています。
venvについて
venvとはPythonの仮想環境を作成する仕組みです。
標準で利用することができます。
仮想環境の用途なのですが
1つの環境には1つのバージョンのパッケージしかインストールすることはできません。
異なるプロジェクトごとに仮想環境を構築することで、プロジェクトごとに異なるバージョンのパッケージを利用することができます。
#パスが通っていれば以下のようになります。
python -V
python 3.12.2
#仮想環境を構築するには
python -m venv 環境名
#不要になり削除する場合は
rm -r -fo 環境名
pipコマンド
pipコマンドはパッケージ(ライブラリ)をインストールするためのコマンドになります。
pip install numpy
#バージョン指定してインストールする場合
pip install numpy==1.14.1
#アンインストールする場合
pip uninstall numpyあるプロジェクトで開発環境と客先環境を同じにする場合です。
開発環境と客先環境でライブラリのバージョンが異なると後々のトラブルに対応しにくいです。
#まず開発環境でインストールされているパッケージの一覧を出力
pip freeze > requirements.txt
#一覧を確認
cat requirements.txt
#客先環境にて同じパッケージをインストールする
pip install-r requirements.txt
Anaconda
AnacondaとはPythonディストリビューションになります。
Anacondaにはデータサイエンスで使用するライブラリを同梱しています。
Anacondaではcondaコマンドが利用でき、Anaconda社が管理する独自のリポジトリからダウンロードされます。
2-2Pythonの基本
- pythonとはプログラミング言語のひとつです。
プログラミングとは何かといえばコンピューターを動かす命令と考えればいいでしょう。
コンピューターが理解できるのは「機械語」と言われる0と1のみの数字になります。
しかし人間が0と1で命令を記述するのは不可能なのです。
そこで人間でも記述できるようにしたのがプログラミング言語になります。

- Pythonはインタプリタ方式
上記の図にあるようにPythonをはじめとするプログラミング言語は機械語プログラムに変換する必要があります。
この変換のことを専門用語でコンパイルといいます。
しかしPythonはコンパイルする必要性はありません。
それはとインタプリタ呼ばれる実行エンジンを搭載しているためです。
このエンジンはPythonプログラムを1行ずつ変換しながら実行してくれます。
メリットはPythonプログラムを書き直してもコンパイルする必要がないという点です。
デメリットは実行速度がややコンパイルする場合に比べて遅いという点でしょうか。
しかしPythonプログラムもコンパイルすることは可能です。
容量の大きなPythonプログラムを書いた場合は速度を速めるためにコンパイルしても良いのかもしれません。 - Pythonはオブジェクト指向言語である。
プログラムというのは命令とデータの集合体なのです。
命令は「関数」でデータは「変数」で表します。
大規模なプログラミングになると数万個の関数と変数が必要になります。
数万個の関数、変数を利用すると非常に把握するのが困難になります。
そこで関係のある関数と変数をクラスと呼ばれるグループ化します。
クラスに所属する関数と変数をメンバーといいます。
Pythonのようなオブジェクト指向言語には自由に利用できる数多くのクラスがあります。
※このようなクラスをライブラリとかモジュールと呼びます。
Pythonの世界ではモジュールという呼び名が一般的です。
コーディング規約
Pythonには基準となるコーディング規約が存在します。
PEP 8と呼ばれます。
以下pythonファイルでの書き方です。
#PEP8に違反した書き方
import sys,os
#PEP8に準拠した書き方
import sys
import os作成したプログラムがPEP8に違反していないかチェックするツールとしてpycodestyleがあります。
#test.pyをチェックする場合
pip install pycodestyle
pycodestyle test.py
#論理的チェックを行う場合、Flake8を用いる
pip install flake8
flake8 test.py
基本構文
IPythonの対話モード
Python標準の対話モードでは以下のように>>>の後にPythonコードを記述して、実行結果が表示されます。
※対話モードを終了する場合はquit()と入力します。
#python標準の対話モード
python
>>>1+4
5
>>>quit()
#ipythonの対話モード
pip install ipython
ipython
In [1]:1+5
Out[1]:6
In [2]:
条件分岐と繰り返し
繰り返しはfor文を使用します。
inは、その後ろに続く要素から1件ずつ取り出してカウンタ変数(year)に格納するという意味のキーワードです。
ipythonで実行してみましょう!
In [2]: for year in [1950,2000,2020]:
...: if year < 1989:
...: print("昭和")
...: elif year < 2019:
...: print("平成")
...: else:
...: print("令和")
昭和
平成
令和
In [3]:
例外処理
try exceptで行います。
例外が発生した場合はexcept節の中が実行されます。
In [7]: try:
...: 1 / 0
...: except:
...: print("0で割れません")
...:
0で割れません
#try exceptなしの場合
In [8]: 1 / 0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
Cell In[8], line 1
----> 1 1 / 0
ZeroDivisionError: division by zero
内包表記
内包表記はリストやセットを簡潔に生成する機能です。
inの後ろに続くリスト(今回はnames)から1件ずつ取り出してカウンタ変数(name)に格納します。
len()は文字数を返します。
appendはメソッドでlen()で返した文字数をlensリストへ追加しています。
最後Out[13]にてlensリストの中身を表示しています。
#リストを作成[]を用いる
In [10]: names = ["spam","ham","eggs"]
#空のリスト作成
In [11]: lens = []
#通常の繰り返し処理
In [12]: for name in names:
...: lens.append(len(name))
...:
In [13]: lens
Out[13]: [4, 3, 4]
#リスト内包表記
In [13]: [len(name) for name in names]
Out[13]: [4, 3, 4]
#セット内包表記{}
In [14]: {len(name) for name in names}
Out[14]: {3, 4}
#辞書内包表記{}key:valueを定義
In [15]: {name:len(name) for name in names}
Out[15]: {'spam': 4, 'ham': 3, 'eggs': 4}
文字列操作
文字列を大文字小文字に変換します。
In [1]: str = "python"
In [2]: str.upper(),str.lower(),str.title()
Out[2]: ('PYTHON', 'python', 'Python')
文字列の置換です。
In [3]: str = "aaaabbbb"
In [4]: str.replace("a","A")
Out[4]: 'AAAAbbbb'
スペースで文字列を分割します。
In [5]: b = "a bc def"
In [6]: b.split()
Out[6]: ['a', 'bc', 'def']左右のスペースを削除する関数も覚えておきましょう。
In [9]: a = " abcdef "
In [10]: a.strip()
Out[10]: 'abcdef'
文字列の末端をチェックします。
In [11]: str = "sample.jpg"
In [12]: str.endswith("jpg")
Out[12]: True
In [13]: str.endswith("png")
Out[13]: False
isdigit()メソッドでは数値の文字列であればTrueを返します。
In [14]: "1234".isdigit()
Out[14]: True
In [16]: "1234aaa".isdigit()
Out[16]: False
文字列の長さを取得します。
In [17]: len("abcdef")
Out[17]: 6
文字列の中に任意の文字列が存在するかチェックします。
In [18]: str = "python"
In [19]: "p" in str
Out[19]: True
In [20]: "a" in str
Out[20]: False
文字列を連結します。
In [21]: "-".join(["a","b","c"])
Out[21]: 'a-b-c'
formatメソッドではテンプレートの文字に対して変数の値を入れて、メッセージを作成する時に使われます。
In [22]: lang,name = "python","taro"
In [23]: "{}は{}が好きです。".format(name,lang)
Out[23]: 'taroはpythonが好きです。'
標準ライブラリ
datetimeモジュール
日付等の処理にはdatetimeモジュールが便利です。
現在の日付を取得します。
In [26]: from datetime import datetime,date
In [27]: datetime.now()
Out[27]: datetime.datetime(2024, 8, 17, 13, 8, 13, 595160)
In [36]: date.today()
Out[36]: datetime.date(2024, 8, 17)
reモジュール
正規表現を扱うにはreモジュールを使用します。
aもしくはbに一致するかどうかを調べたいならa|bと記述します。
調査対象となる文字列の先頭にaもしくはbがあるか調べてみます。
先頭にaもしくはbがあればmatch=”a”、match=”b”と返します。
matchは先頭で一致するものを返すメソッドです。
In [28]: import re
In [29]: re.match("a|b","abcdef")
Out[29]: <re.Match object; span=(0, 1), match='a'>
In [30]: re.match("a|b","bcdef")
Out[30]: <re.Match object; span=(0, 1), match='b'>
In [31]: re.match("a|b","cdef")
In [32]:
文字列全体から一致する最初の場所を探すのはsearchを用います。
In [33]: re.search("a","ppbwertyuiboaa")
Out[33]: <re.Match object; span=(12, 13), match='a'>
In [34]: re.search("a","ppbwertyuibo")
In [35]: re.search("b","ppbwertyuibo")
Out[35]: <re.Match object; span=(2, 3), match='b'>
loggingモジュール
ログレベルを指定して任意のファイルにログ出力ができます。
以下に重要度が低い順にログレベルを並べます。
debug(デバッグレベル)
info(infoレベル)
warning(警告レベル)
error(エラーレベル)
critical(重大なエラー)
Jupyter Notebook
pipを用いてインストールします。
やや時間がかかるかもしれません。
pip install jupyter
jupyter notebookJupyter Notebookは、Webブラウザ上でPython(Julia、R言語も可)コードを実行できる環境です。
IPythonをWebブラウザ上で実行するものと思えばよいかと思います。
下記のようにその場で実行結果が表示されます。
表形式やグラフも表示可能です。
Cellといわれる領域にプログラムを記述します。
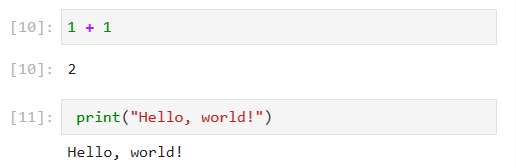
Jupyter Notebookは、%または%%からはじまるマジックコマンドというコマンドが使えます。
%timeit、%%timeitはプログラムの実行時間を計測するコマンドです。
前者は1行のプログラムに対して、後者はセル全体の処理時間を計測します。
!を入力することでシェルコマンドが利用できます。
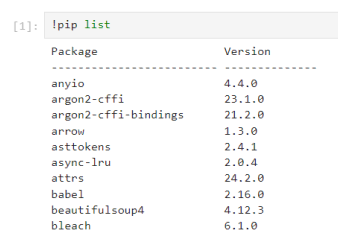
第3章 数学の基礎
お疲れ様です。
第3章数学の基礎はこちらになります。