python pandas 超初心者向け使い方
- fukutaku
- 2022年1月3日
pandasというのは表データを読み込んで表示、抽出、行追加、列追加等ができるライブラリになります。
表データというのは行列で構成されたデータです!
ExcelやCSVがまさにそれです。
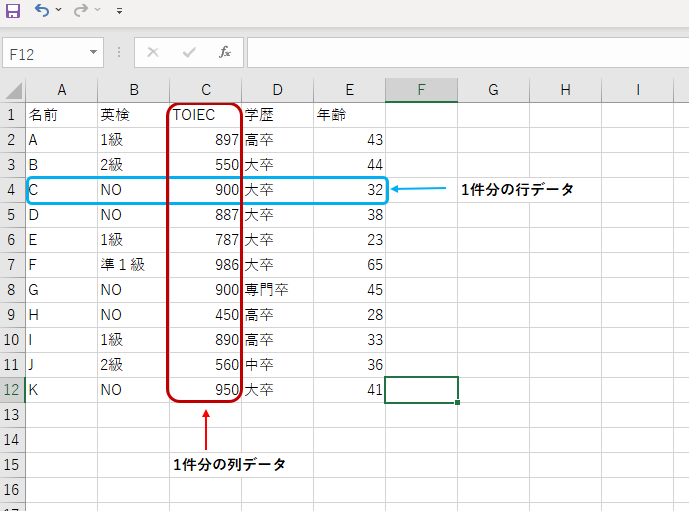
下記のようなデータです。
もくじ
- pandasとは?
- CSVファイルの読み込みと表示
- データ型とは?
- データ抽出
- 条件抽出
- 列データ、行データの追加と削除
- データを理解
1.pandasとは?
コマンドプロンプトを用いてpandasをインストールします。
pip install pandas
と入力して実行します。
pip install pandaspandasはSeriesとDataFrameというデータ型を提供しています。
Seriesは1次元データでDataFrame2次元データになります。
#Series作成
In [1]: import pandas as pd
In [2]: seri = pd.Series([10,20,30,40])
In [3]: seri
Out[3]:
0 10
1 20
2 30
3 40
#DataFrame作成
In [5]: dataf = pd.DataFrame([[10,"a"],
...: [20,"b"],
...: [30,"c"],
...: [40,"d"]])
In [6]: dataf
Out[6]:
0 1
0 10 a
1 20 b
2 30 c
3 40 d
numpyのndarray型からDataFrameを作成することもできます。
In [7]: import numpy as np
In [8]: dataf = pd.DataFrame(np.arange(100).reshape((25,4)))
In [9]: dadtaf
Out[10]:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
(省略)
23 92 93 94 95
24 96 97 98 99
headメソッドにて先頭5行のみを出力します。
In [11]: dataf.head()
Out[11]:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
#tailメソッドは末尾5行を出力します。
インデックス名とカラム名に任意の文字列を設定します。
In [13]: dataf = pd.DataFrame(np.arange(6).reshape((2,3)))
In [14]: dataf
Out[14]:
0 1 2
0 0 1 2
1 3 4 5
In [15]: dataf.index = ["01","02"]
In [16]: dataf.colums = ["A","B","C"]
In [17]: dataf
Out[17]:
A B C
01 0 1 2
02 3 4 5
データの抽出です。
In [21]: dataf["A"]
Out[21]:
01 0
02 3
Name: A, dtype: int64
In [22]: dataf[["A","B"]]
Out[22]:
A B
01 0 1
02 3 4
In [31]: dataf[0:2]
Out[31]:
A B C
01 0 1 2
02 3 4 5
loc、ilocというメソッドを利用したデータの抽出です。
必ずインデックス、カラムの両方を指定する必要があります。
In [35]: dataf.loc[["01","02"],["A","B","C"]]
Out[35]:
A B C
01 0 1 2
02 3 4 5
In [37]: dataf.loc[:,:]
Out[37]:
A B C
01 0 1 2
02 3 4 5
In [40]: dataf.loc["01",["A","C"]]
Out[40]:
A 0
C 2
Name: 01, dtype: int64
ilocメソッドです。
インデックス番号、カラム番号を指定して抽出します。
In [44]: dataf
Out[44]:
A B C
01 0 1 2
02 3 4 5
In [45]: dataf.iloc[0,0]
Out[45]: np.int64(0)
In [46]: dataf.iloc[0:2,0:2]
Out[46]:
A B
01 0 1
02 3 4
2.CSVファイルの読み込みと表示
それではまずはCSVファイルを読み込むコードを書きます。
pandasをインポートします。
import pandas as pd
pd.read_csv()でCSVファイルを読み込みます。
Book1.csvをデスクトップに保存します。
()内にはファイルパスを記入します。
読み込んだデータをsample_dateに格納します。
sample_date = pandas.read_csv()
In [56]: sample_date =pd.read_csv("C:/Users/user/Desktop/Book1.csv",encoding="utf-8")
In [57]: sample_date
Out[57]:
a b c
0 0 1 2
1 3 4 5
それでは実行してみましょう。
下記のように表示されればOKです。

※下記のようなエラーが出る場合がります。
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x96 in position 0: invalid start byte
読み込みCSVファイルの種類ですが下記の通りUTF-8で保存してください。
解決すると思います。

3.データ型とは?
sample_dateのデータ型を調べてみましょう。
print(type(sample_date))と記述します。
class ‘pandas.core.frame.DataFrame’と表示されます。
DataFrameというのは Pandas における二次元配列のデータ型を意味しています。
二次元配列,つまり表形式です。
表形式は行と列がありますから2次元なのです。
表形式というと馴染みのものにはExcelがありますが、ExcelやCSVを読み込むとPandasではDataFrameというデータ型になります。
プログラム初心者の方は分かりづらいところですが、
データには型があってそれらを意識してプログラムする必要があります。
4.データ抽出
読み込んだデータの位置を指定して表示させることができます。
データ名.iloc[行番号,列番号]で記述します。
cell = sample_date.iloc[0,0]
print(cell)と記述します。
Aが表示されます。
cell = sample_date.iloc[0,1]
print(cell)と記述します。
1級が表示されます。
※行番も列番も0からスタートする点を注意してください。

次は範囲指定で抽出してみましょう。
名前と英検の列だけ抽出したいとします。
cell = sample_date.iloc[0:11,0:2]
print(cell)と記述します。
※11行目、2列目は含まない点を注意してください。
下記のように抽出されました。

直接列名を指定して表示させることもできます。
データ名.loc[]を用います。
cell = sample_date.loc[0:10,[“名前”,”英検”]]
print(cell)と記述します。
結果は先ほどと同じです。
※locの場合はilocと異なり行番をマイナス1しないので注意してください。
5.条件抽出
特定の条件にあうデータだけ抽出したいとします。
query()関数を用います。
データ名.query()のように記述します。
()内は条件式が入ります。
年齢40以上の方を抽出したいとします。
その場合、
cell = sample_date.query(“年齢 >= 40”)
print(cell)と記述します。
下記のように40以上の行が表示されます。

それでは学歴の列で大卒だけを抽出したい場合は
下記のように記述します。
cell = sample_date.query(“学歴 == ‘大卒'”)
print(cell)と記述します。
実行してみます。
下記のように大卒者の行だけが表示されます。

次に複数条件抽出をやってみましょう!
cell = sample_date.query(“年齢 >= 40 and 学歴 == ‘大卒'”)
print(cell)と記述します。
実行してみます。
下記のように年齢40以上かつ大卒者の行だけが表示されます。
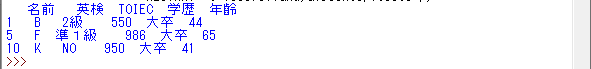
独学に疲れたらプログラミングスクールも良いでしょう。
確かにお金はかかりますが
無駄に悩む時間を節約できます。
私もテックアカデミーにはお世話になりました。
下記リンク👇
6.列データ、行データの追加と削除
列データを追加する場合以下のように記述します。
データ名[“追加列名”] = [“0行目要素”,”1行目要素”,”2行目要素”・・・・]
それでは性別という列を追加してみます。
コードは下記のようになります。
sample_date[“性別”] =[“男”,”男”,”女”,”女”,”女”,”男”,”女”,”女”,”男”,”女”,”女”]
print(sample_date)
実行します。
下記のように性別という列が追加されます。

行データを追加する場合以下のように記述します。
データ名.loc[追加行番号] = [“0列目要素”,”1列目要素”,”2列目要素”・・・・]
それではLさんという人を追加してみます。
コードは下記のようになります。
sample_date.loc[11] =[“L”,”1級”,”900″,”大卒”,”50″,”男”]
print(sample_date)
実行します。
下記のように11行目にLさんが追加されます。

最後に削除方法です。
列削除する場合以下のように記述します。
データ名.drop(“列名”,axis = 1)
それでは名前の列を削除します。
コードは下記のようになります。
sample_date = sample_date.drop(“名前”,axis = 1)
print(sample_date)
実行します。
下記のように名前の列が消えました。

行削除する場合以下のように記述します。
データ名.drop(行番号,axis = 0)
それでは0行目を削除します。
コードは下記のようになります。
sample_date = sample_date.drop(0,axis = 0)
print(sample_date)
実行します。
下記のように0行目が消えました。

プログラミングスクールテックアカデミーでは無料相談もやっています。
いきなり申込むのはちょっと・・・
というのであれば一度相談してみるのも良いでしょう。
受講にあたっての不安をぶつけてみてください。
一人で悩むのは時間の無駄と思い私もお世話になったテックアカデミー。
pythonやAIを学びました。
申し込み先は下記です。
7.データ理解
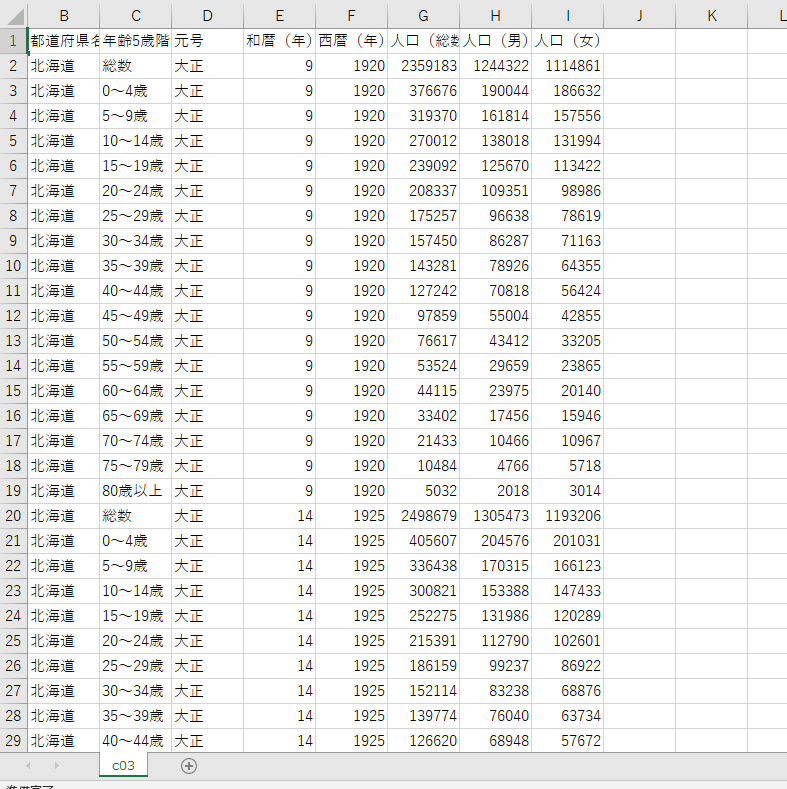
最後に実践的なデータを読み込んでそのデータを詳しく調べていきましょう!
今回は政府統計のサイトから国勢調査を利用します。
下記を利用👇
pandas.read_csv()でCSVファイルを読み込みます。
()内にはファイルパスを記入します。
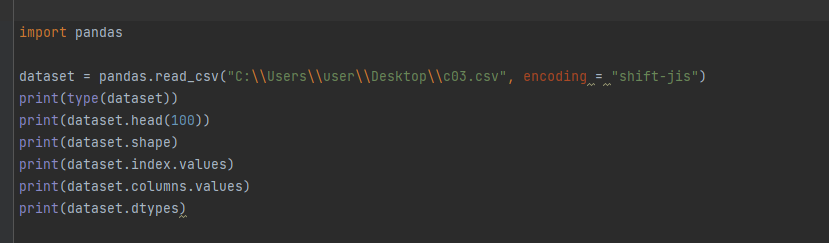
読み込みしたCSVファイルを変数:datasetに格納します。
dataset = pandas.read_csv(“C:\Users\user\Desktop\c03.csv”, encoding = “shift-jis”)
※encoding = “shift-jis”について
コンピュータでは文字コードというものがあります。
サンキュウという言葉が日本人は産休、アメリカ人にはThankyouとなるよう
な違いです。
今回利用している国勢調査のCSVファイルはshift-jisを利用しています。
何も指定しなければUTF-8で読み込みますので文字化けが起こります。
そのためのencoding = “shift-jis”なのです。
その他の回避策として読み込みCSVファイルの種類ですが下記の通りUTF-8で
保存します。その場合、encoding = “shift-jis”は不要です。
dataset.head()にてデータを表示してみましょう。
()内に数字を入れますとその行分表示されます。
print(dataset.head(100))
※数字を入れなければ5行だけ表示されます。
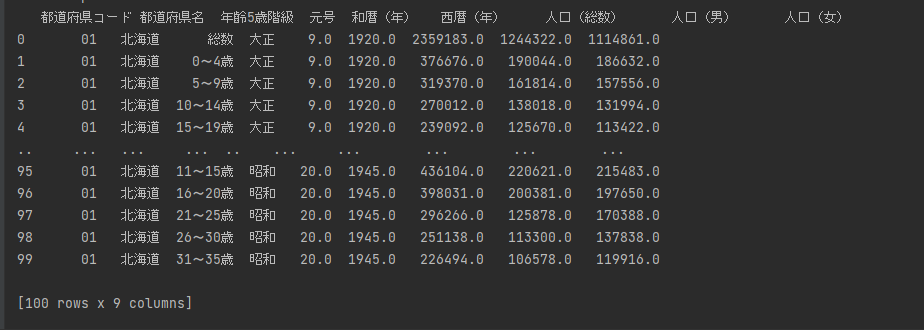
datesetのデータ型を調べてみましょう。
print(type(dataset))と記述します。
class ‘pandas.core.frame.DataFrame’と表示されます。
DataFrameというのは Pandas における二次元配列のデータ型を意味しています。
二次元配列,つまり表形式です。
表形式は行と列がありますから2次元なのです。
データの形状みていきましょう。
dataset.shapeを用います。
print(dataset.shape)
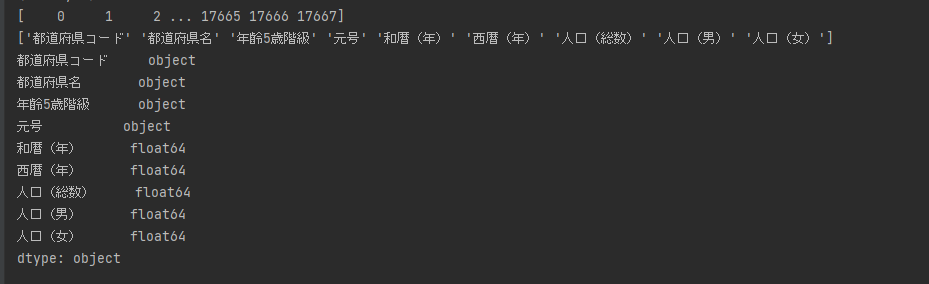
(17668, 9)と表示されました。
これは17668行、9列のデータであるという意味です。
行番号と列名を表示してみましょう。
行はprint(dataset.index.values)
列はprint(dataset.columns.values)
列の型もあわせて表示してみましょう。
print(dataset.dtypes)
実行します。
下記のように表示されます。
※型というのはデータの種類でint(整数)、float(実数)、str(文字列)等です。
ソースコードです。
今回紹介させて頂いたものを一通りまとめています。
以下は私がこの記事を執筆するにあたって参考にした書籍になります。
非常に優しく記載されておりますので初心者には非常に良いと思います。
