pythonでスクレイピングとエクセル書き込みの自動処理(実践編)
- fukutaku
- 2021年12月2日
これまで簡易的なpythonのスクレイピング方法を解説してきました。
ここでは実践的な処理を制作してみます。
過去の記事👇
python requests でスクレイピングと書き込み(初心者向け)
python Beautiful Soup タグ指定でスクレイピング(初心者向け)

以上の処理をpythonで自動化します。そのコードを解説していきます。
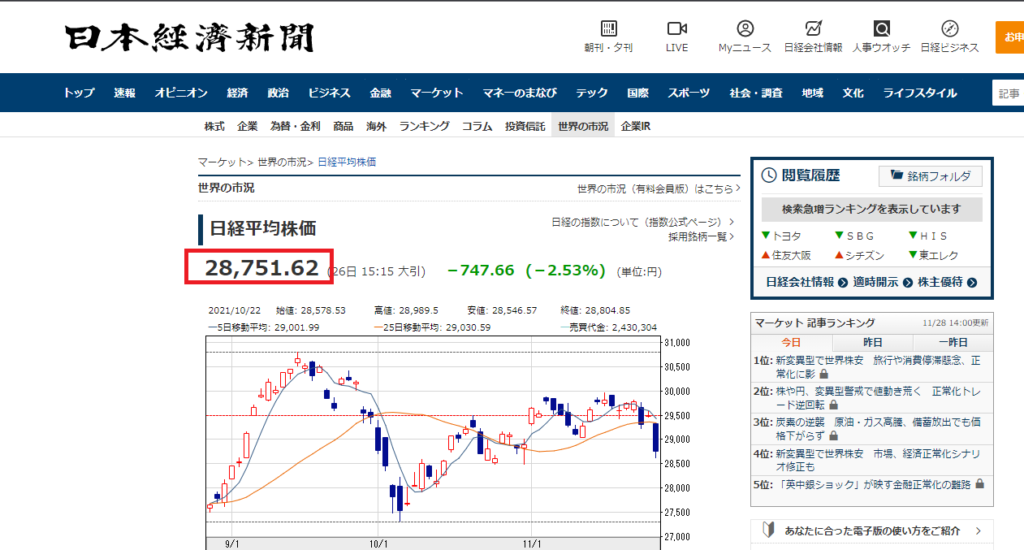
データの取得先は下記になります。
実際にコードを書いていきます。
書き込み用Excelファイルを予め用意します。
デスクトップにstock_prices.xlsxを作ります。
それではコードを書いていきます。
import requests
→requestsライブラリをインポートします。
from bs4 import BeautifulSoup
→BeautifulSoupライブラリをインポートします。
import openpyxl
→openpyxlライブラリをインポートします。
openpyxlはpython上でexcelを操作するためのライブラリになります。
url = “https://www.nikkei.com/markets/worldidx/chart/nk225/”
→取得先のwebサイトのURLを入力します。
取得先URLを変数:urlに代入します。
response = requests.get(url)
→requestsライブラリに.get(url)をつけることで
url(https://www.nikkei.com/markets/worldidx/chart/nk225/)を取得
して、それを変数:responseに格納するという意味です。
soup = BeautifulSoup(response.content,”html.parser”)
この1行でHTMLのデータ.contentをhtml.parserに渡すことを意味しています。
解析処理結果を変数:soupに入れます。
※html.parserはHTMLを解析してくれる処理になります。
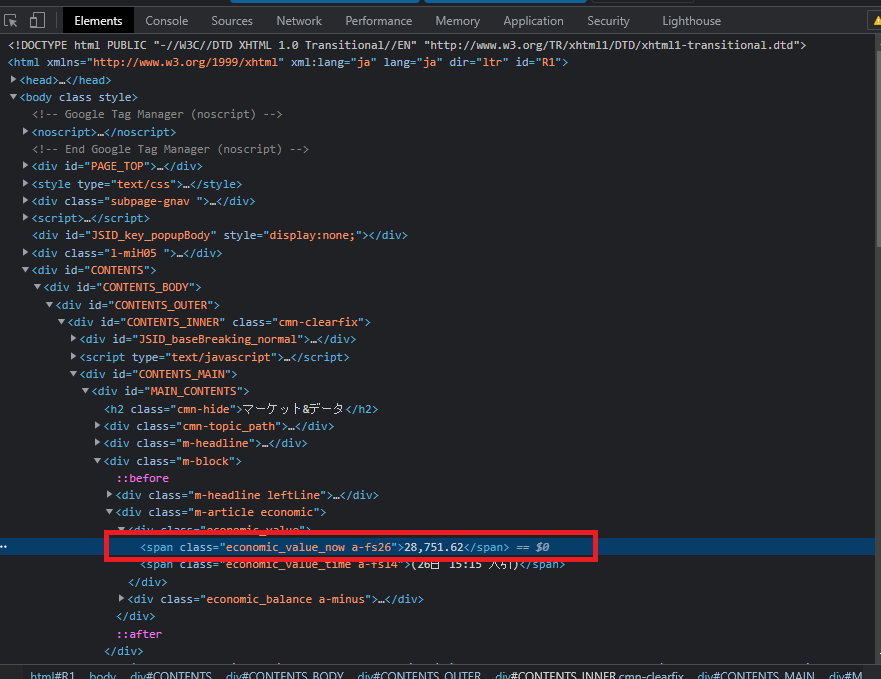
sp = (soup.find(class_=”economic_value_now a-fs26″).text)
取得webページのデータの中でも必要なデータは日経平均株価です。
以下のソースコードをご覧ください。
class属性が設定されており、目印として使えそうです。
※chromeのデベロッパーツールを用いています。
コード解析には便利なツールです。
wb = openpyxl.load_workbook(“stock_prices.xlsx”)
stock_prices.xlsxのデータを取得して、変数:wbに格納しています。
※今回はpythonファイルとExcelファイルが同階層に存在するため
stock_prices.xlsxとファイル名入力だけでいいのですが、そうでない場合
フルパスを記入するようにしてください。
ws = wb.worksheets[0]
今回はシートは1つしかないのですが、シートも指定する必要があります。
stock_prices.xlsxのシートインデックス0番を変数:wsに格納するということです。
maxrow = ws.max_row +1
さてセルに株価を入力していきます。
Excelファイルは下記のようにしています。

今日はA2に記入したいですが、明日はA3、その翌日はA4ですね。
そのため最終行を取得します。
ws.max_rowで指定シートの最終行を取得し、その次の行に記入したいわけですので+1をします。
ws.cell(row = maxrow,column = 1).value = sp
シートwsのA列の最終行へ変数:spを設定します。
wb.save(“stock_prices.xlsx”)
保存します。
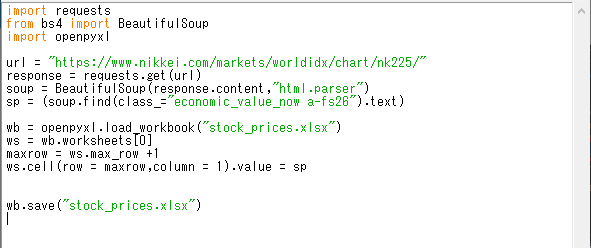
まとめると下記のようになります。
それでは実行してみましょう。
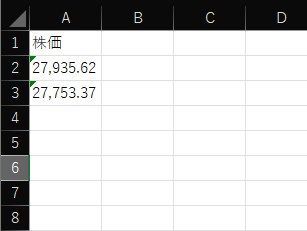
下記のように記入されていれば成功です。
もう一度実施するとA3に記入されます。
※A2は昨日プログラムを実施しましたので2021年12月1日の株価、A3には本日
プログラムを実行したので2021年12月2日の株価が記載されています。
以下参考書籍になります。
優しく書かれていますので初心者向けに最適です。

詳しく勉強するならやはりこちらです。
開発環境からpython文法、スクレイピングまで幅広く紹介されています。
