python Beautiful Soup タグ指定でスクレイピング(初心者向け)
- fukutaku
- 2021年11月28日
前回記事ではライブラリrequestsを用いてwebサイトのソースコードを取得するプログラム(スクレイピング)の解説しました。
今回はタグを指定してスクレイピングする情報を絞ってみましょう。
スクレイピングするためのBeautiful Soupをコマンドプロンプトを用いてインストールします。
pip install beautifulsoup4
と入力して実行します。requestsインストール時と同じです。
pipは内部コマンドまたは外部コマンドとして認識されておりません
とのエラーが出現した場合は下記を参考にしてみてください。
IDLEを用いて開発、実行を進めます。
IDLEについては前回記事をご覧ください。
python requests でスクレイピング(初心者向け)
それではコードを書いていきます。
import requests
→requestsライブラリをインポートします。
from bs4 import BeautifulSoup
→BeautifulSoupライブラリをインポートします。
url = “https://fukutakublog.com/it/python/an-introduction-to-python”
→取得先のwebサイトのURLを入力します。
取得先URLを変数:urlに代入します。
※変数とは箱のような入れ物をイメージしてみてください。
response = requests.get(url)
→requestsライブラリに.get(url)をつけることで
url(https://fukutakublog.com/it/python/an-introduction-to-python)を取得
して、それを変数:responseに格納するという意味です。
soup = BeautifulSoup(response.content,”html.parser”)
この1行でHTMLのデータ.contentをhtml.parserに渡すことを意味しています。
解析処理結果を変数:soupに入れます。
※html.parserはHTMLを解析してくれる処理になります。
print(soup.find(“title”).text)
titleタグを抽出し、.textを追加することでタグ内の文字列だけをprint関数用いて表示します。
※タグについて
タグは<p>,<a>,<br>,<div>など様々なものがあります。
それぞれ表示の仕方によって使い分けますが今回は<title>の内容を抽出するプ
ログラムです。
<title>は名前の通りページタイトルに用いるタグになります。
下記はソースコードになります。
タグは下記のように通常、入れ子のようにして使います。
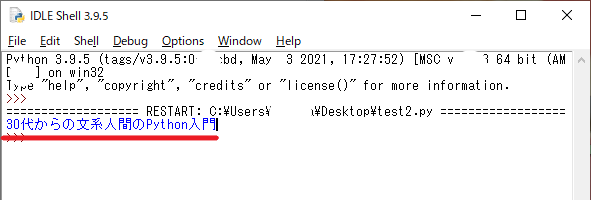
結果”30代からの文系人間のPython入門”を抽出することになります。
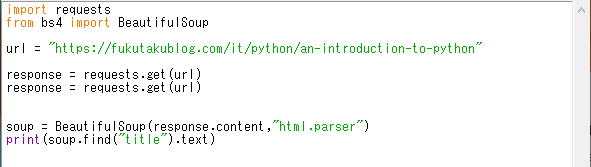
以下が完成のコードです。
実行後、以下のようにタイトルが抽出されていれば成功です。
尚、前回のように外部ファイルに出力したい場合のコードは下記になります。
ご参考にしてみてください。
※”title”の箇所のタグ名を変更してみるとそのタグ情報が取得できます。

※補足
id属性、class属性で取得も可能です。
soup.find(id = “id名”)
soup.find(class_ = “class名”)
以下参考書籍になります。
