PythonでOCRを実装する!
- fukutaku
- 2022年5月3日
pythonでOCR処理ができます。
今回はそのやり方を解説したいと思います。
GoogleのオープンソースOCRツールであるTesseractを使います。
下記のページからインストールします。
windows用インストーラになります。
64ビット版をダウンロードします。
日本語はないようです。
他のアプリケーションをすべて閉じてからセットアップしてください。
利用規約になります。
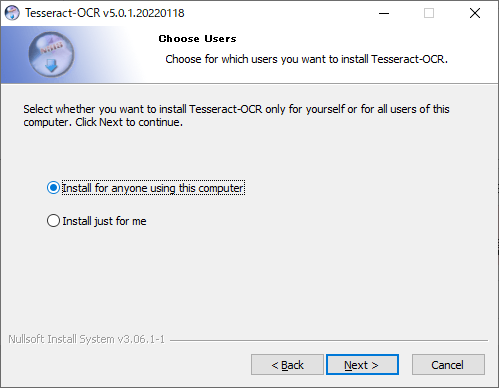
PCを利用している他のアカウントにもインストールするか、
自分だけにインストールするかを聞いています。
私の場合、自分しかこのPCは利用していないためどちらでもいいのです。
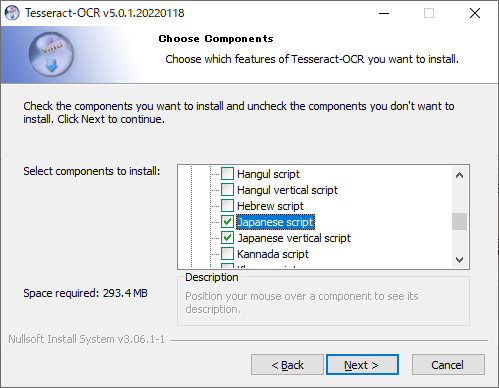
日本語の読み込みを可能にするため下記を追加でチェックします。
Additional script data内の下記の2項目にチェックを入れます。
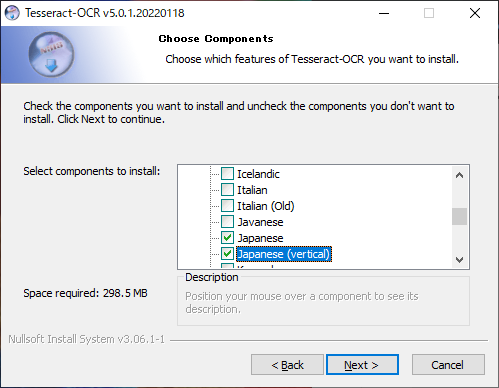
更にAdditional script data内の下記の2項目にもチェックを入れます。
Nextをクリックします。
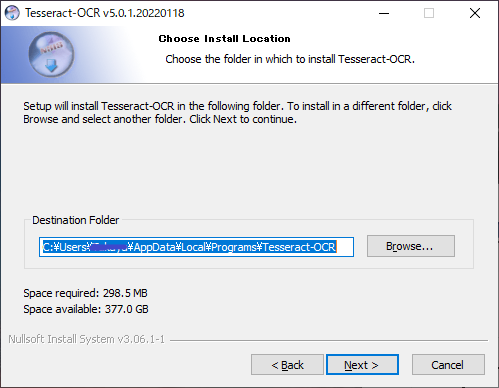
ここはインストールするフォルダを聞いています。
特に変更する必要はないと思います。
※どこにインストールされたかは後々大切になってきますので確認しておく必要があります。
インストールを実行します。
Finishを押下すれば完了です。
まずはコマンドプロンプトにてtesseractを実行してみます。
tesseractがインストールされているフォルダに移動します。
cdはフォルダの移動を意味します。
cd C:\Users\ユーザ名\AppData\Local\Programs\Tesseract-OCR
※パスは一緒とは限りませんのご注意ください。
※AppDataがみあたらない場合、隠しフォルダになっています。
エクスプローラーの表示タブ→隠しフォルダにチェックを入れます。
インストールされているか確かめてみましょう。
tesseract –version
下記のように表示されればとりあえずはOKです。

それではOCRしてみましょう!
Tesseract-OCRフォルダ内に画像ファイルを入れます。
用いる画像はyahooニュースの一部です。

コマンドプロンプト上で下記のように記述します。
※今いるディレクトリがTesseract-OCRになっていることを確認しましょう。
tesseract yahoo.png yahoo -l jpn
→yahoo.pngはocrしたいファイル名になります。
yahooは出力ファイル名になりますので実行するとyahoo.txtが出力されま
す。
最後の-l jpnですが日本語をocrしたい場合につけるオプションです。
-l jpnのlはアルファベットです。数字ではありません。

※・・・・permission deniedといったエラーが出現した場合、コマンドプロンプトを管理者として実行してみてください。
notepad yahoo.txt
→メモ帳でyahoo.txtを開くということです。
さあどうでしょうか。
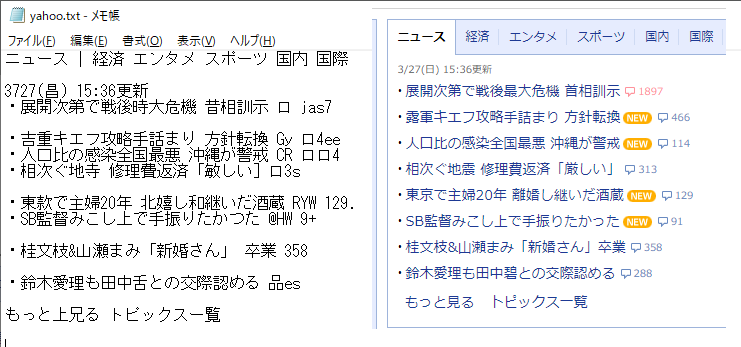
これをどう判断するかは読者様にお任せします。
尚、手書き文字はもっと苦しいです。
Pythonでコードを書く
それではpythonコードでTesseractを起動します。
まずはpyocrをコマンドプロンプトからインストールします。
py -m pip install pyocr
→pyocrだけでなく画像処理をおこなうライブラリpillowもインストールされ
ます。
※pyocrはpythonからTesseract(OCR)を利用するために必要です。

※下記のようなエラーが出る場合がります。
pipは内部コマンドまたは外部コマンドとして認識されておりません。
解決方法はこちらがわかりやすいと思います。
それではコードを書いていきます。
from PIL import Image
import pyocr
画像処理ライブラリImageとOCR利用のためのpyocrをインストールします。
engines = pyocr.get_available_tools()
engine = engines[0]
getメソッドを用いて利用可能なocrツールをenginesに格納します。
今回はTesseractしかありませんので0番目を指定しています。
※getメソッドとはキーと値をセットとした辞書型と言われる配列からキー指定
して値を取得することができます。
例えば
prefs = {0:”Hokkaido”, 1:”Ishikawa”, 2:”Tokyo”, 3:”kyoto”}
pref = prefs[1]
print(pref)
結果はIshikawaと表示されます。
prefsという配列のキー0番目が値=Hokkaidoになります。
enginesという配列のキー0番目にTesseractが入っていることになります。
print(engine)でTesseract.pyが表示されます。
ocr = engine.image_to_string(Image.open(“yahoo.png”), lang=”jpn”)
print(ocr)
読み取りしたいファイル名を指定します。yahoo.png
lang=”jpn”は日本語を意味します。
読み込んだテキストを変数ocrに格納して表示されます。
以下のように表示されれば成功です。

※Pythonファイルと読み取りファイルはTesseract-OCRフォルダ内に入れておく
必要があります。
私はまだまだプログラミング初学の身ですが
書籍として非常に参考なったのが下記のシリーズです。
やりたいことをベースにPGを学べますので退屈しないのが非常に良い点です。
解説も優しいです。

