Python 3 データ分析試験の勉強方法②
- fukutaku
- 2023年12月3日
認定テキストは下記です。
1章から5章までありますが、今回は2章のPythonと環境の解説です。

こちらを読み込めば大丈夫なのですが
完全に読み込むのは初学者にはきついです。
そのためなるべく優しく要約してみました。
※過去問は配布されておりません。
もくじ
- 実行環境の構築
- pythonの基礎
- Jupyter Notebook
1.実行環境の構築
まずPython公式サイトからダウンロードします。
python.exe は Python をインストールしたディレクトリに保存されています。
そのディレクトリまでのPATHを設定することで、フルパスで指定する必要がなくなります。
インストール中に[Add Python to Path]という項目にチェックを入れることでPATHが設定されます。
コマンドプロンプトでpython -Vと入力して以下のようにバージョンが表示されれば
無事にパスが設定されています。
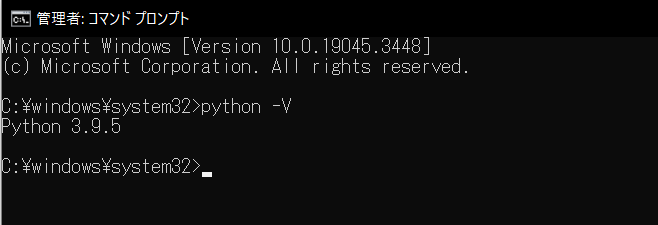
もしパスを通していなければ下記のようにPythonをインストールしたディレクトリまで記載する必要があります。

venvについて
venvとはPythonの仮想環境を作成する仕組みです。
標準で利用することができます。
仮想環境の用途なのですが
1つの環境には1つのバージョンのパッケージしかインストールすることはできません。
異なるプロジェクトごとに仮想環境を構築することで、プロジェクトごとに異なるバージョンのパッケージを利用することができます。
Windowsでvenv環境を作成する
仮想環境はpython -m venv 環境名で作成します。
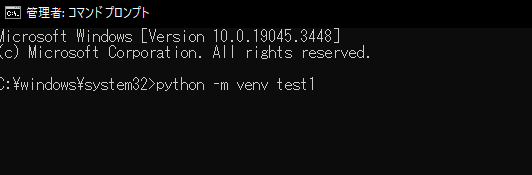
すると指定した環境名でディレクトリが作られます。
次に、test1(仮想環境) ディレクトリにある Scripts\activate.bat を実行します。
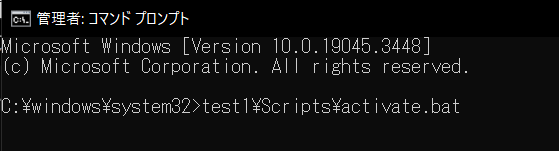
コマンド プロンプトの先頭に (test1) と表示さていれば仮想環境で実行中です。
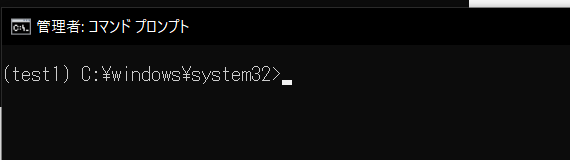
deactivateコマンドにて仮想環境を抜けることができます。
pipコマンド
pipコマンドはPyPIというサイトで公開されているデータ分析関連パッケージをインストールするための
コマンドになります。
PyPI – the Python Package Index
パッケージをインストールする場合、pip installコマンドを用います。
コマンドプロンプトを起動します。
pip install パッケージ名

上記ではpipのバージョンが古いと警告がでています。
pipパッケージを最新版に更新します。
pip install -U pip
特定のバージョンを指定してインストールすることもできます。
pip install パッケージ名==バージョン
アンインストールする場合は
pip uninstall パッケージ名
途中で確認されますのでYと入力します。

pip listコマンドにてインストールされているパッケージの一覧を取得することができます。
pip list -oにて新しいバージョンが存在するパッケージ一覧を表示します。
パッケージバージョンの統一
開発環境と動作環境のパッケージバージョンは統一しないと予期しないエラーが発生する可能性があります。
まず開発環境でnumpyをインストールします。
pip install numpy
インストールされているパッケージのバージョンを保存します。
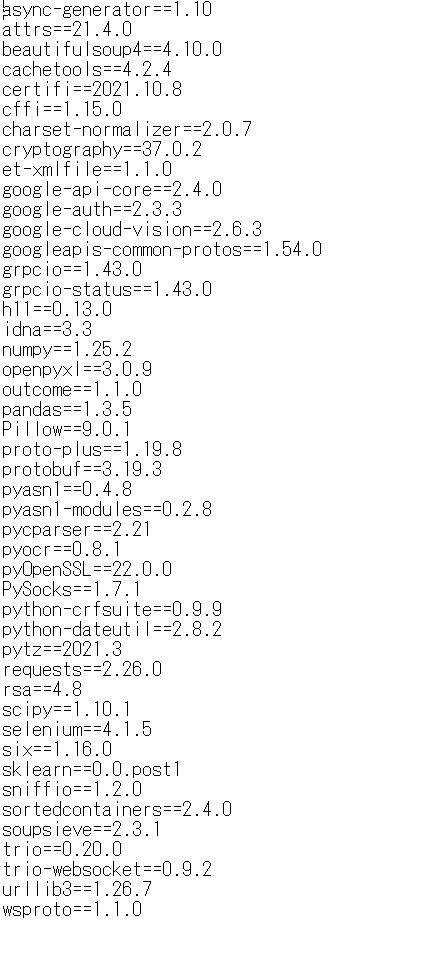
pip freeze > requirements.txt
結果を表示します。
requirements.txt

以下のようにインストール済みパッケージの一覧が表示されました。
requirements.txtは作業中フォルダに格納されています。
筆者の環境では下記になります。
C:\Windows\System32\requirements.txt
requirements.txtを開発環境から動作環境の作業フォルダへ移動します。
動作環境にて
pip install -r requirements.txtを実施することでrequirements.txtと同様のバージョンパッケージがインストールされます。
Anaconda
これまではPython、ライブラリのインストール方法を解説してきましたが
これとは異なる環境構築の方法としてAnacondaがあります。
AnacondaをインストールすればPython、ライブラリが同梱されています。
このような包括的なものをディストリビューションといいます。
Anacondaにはpipコマンドの他、独自のcondaコマンドが付属しています。
condaコマンドにてパッケージをanacondaのリポジトリからインストールします。
※リポジトリとはパッケージの倉庫のようなものです。
2.pythonの基礎
コーディング規約
Pythonには標準となるコーディング規約が存在します。
PEP8というドキュメントにまとめられています。
import numpy, sys → PEP8に違反した書き方
import numpy → PEP8に準拠した書き方
import sys
import numpy, sysと記述してtest.pyで保存します。
作成したプログラムがPEP8に違反していないかチェックするツールとしてpycodestyleがあります。
コマンドプロンプトにてpip install pycodestyleと記述してインストールします。
pycodestyle ファイル名

以下が出力されます。

PEP8に加えて、定義したが使用していない変数やモジュールをチェックするFlake8というツールがあります。
pipコマンドでインストールして利用します。
pip install flake8
flake8 test.py
基本構文
IPythonの対話モード
Python標準の対話モードでは以下のように>>>の後にPythonコードを記述して、実行結果が表示されます。
※対話モードを終了する場合はquit()と入力します。

IPythonの対話モードではプロンプトがIn [1]:のようになります。
またTABキーによる補完や自動インデント機能があります。
ipythonをインストールします。
pip install ipython

条件分岐と繰り返し
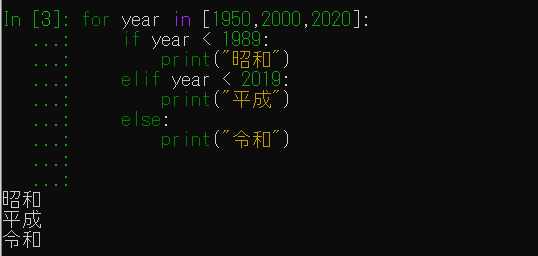
繰り返しはfor文を使用します。in は、その後ろに続く要素から1件ずつ取り出してカウンタ変数(year)に格納するという意味のキーワードです。
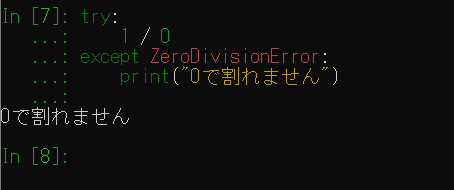
例外処理
try exceptで行います。
例外が発生した場合はexcept節の中が実行されます。
内包表記
内包表記はリストやセットを簡潔に生成する機能です。
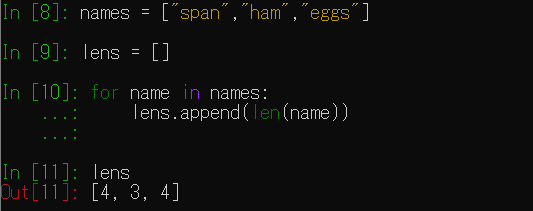
まず内包表記を利用せず文字数を格納したリストを作成します。in の後ろに続くリスト(今回はnames)から1件ずつ取り出してカウンタ変数(name)に格納します。
len()は文字数を返します。
appendはメソッドでlen()で返した文字数をlensリストへ追加しています。
最後Out[11]にてlensリストの中身を表示しています。
次に内包表記を利用します。

セットを内包表記で作成します。
セットとは集合で同じデータは重複できません。
{}で定義します。

辞書を作成します。
※多言語では連想配列というやつです。
{}で囲んでkey:valueで定義します。
keyは重複できません。

以下のようにネストも可能です。

ジェネレーター式
以下のように100までの2乗のリストを作成します。
これが10万や100万といった数になると大量のメモリを確保する必要があります。
これを避けるためジェネレーター式で作成することでメモリが節約できます。

ジェネレーター式では値を1つずつ返します。
()で定義します。

タイプがリストからジェネレーターになっています。
値を順番に取り出すことができます。

ファイル入出力
ファイルの書き込みにはopen関数を用います。
writeメソッドにて書き込みをします。

readメソッドにて読み込みを行い、変数:dataに格納します。

中身を表示します。

文字列操作
文字列を大文字小文字に変換します。

文字列の置換です。

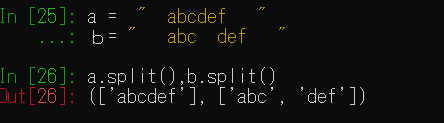
a = “ abcdef ”
b= ” abc def “
a.split()
b.split()
以下のようにスペースで文字列を分割します。
左右のスペースを削除する関数も覚えておきましょう。
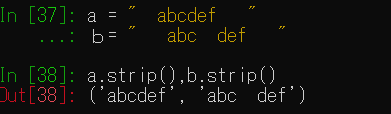
a = “ abcdef ”
b= ” abc def “
a.strip()
b.strip()
文字列の末端をチェックします。
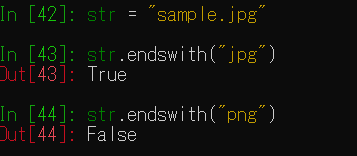
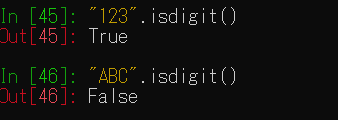
isdigit()メソッドでは数値の文字列であればTrueを返します。
文字列の長さを取得します。

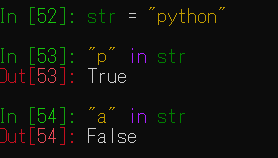
文字列の中に任意の文字列が存在するかチェックします。
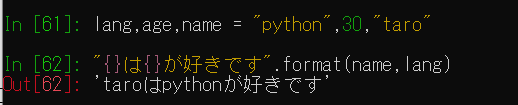
文字列を連結します。

formatメソッドではテンプレートの文字に対して変数の値を入れて、メッセージを作成する時に使われます。
標準ライブラリ
・datetimeモジュール
日付等の処理にはdatetimeモジュールが便利です。
現在の日付を取得します。

・reモジュール
正規表現を扱うにはreモジュールを使用します。
aもしくはbに一致するかどうかを調べたいならa|bと記述します。
調査対象となる文字列の先頭にaもしくはbがあるか調べてみます。
先頭にaもしくはbがあればmatch=”a”、match=”b”と返します。
matchは先頭で一致するものを返すメソッドです。
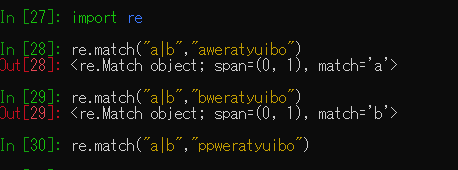
文字列全体から一致する最初の場所を探すのはsearchを用います。
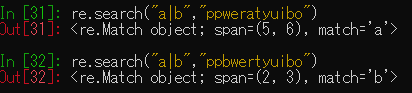
また正規表現は様々なものがございます。
a+のように記述しますとaを1回以上繰り返したものにマッチします。

今日の日付を取得します。

・pickleモジュール

3.Jupyter Notebook
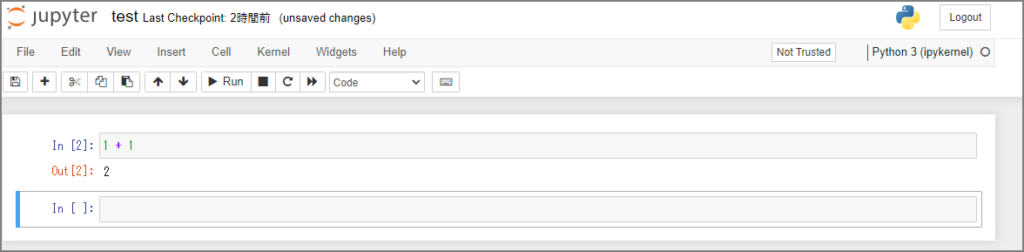
JupyterNotebookはWebブラウザ上でプログラムの実行と結果の参照が行えるツールです。
前章で紹介したIPythonをWebブラウザ上で実行するものと思えばよいかと思います。
anacondaをインストールした方は下記から実行することができます。

Home画面のNewからPython3を選択します。
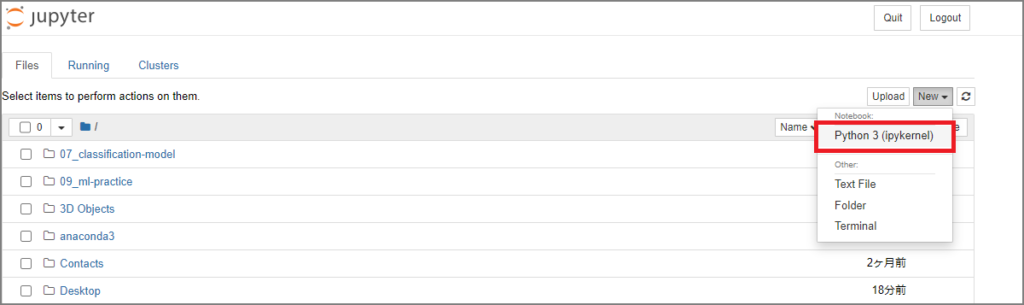
以下のような画面が表示されます。
Notebookと呼ばれています。
拡張子は.ipynbになります。

下記をクリックすることでファイル名を変更することができます。
Renameをクリックして確定します。
今回はtestとしました。

test.ipynbが表示されています。
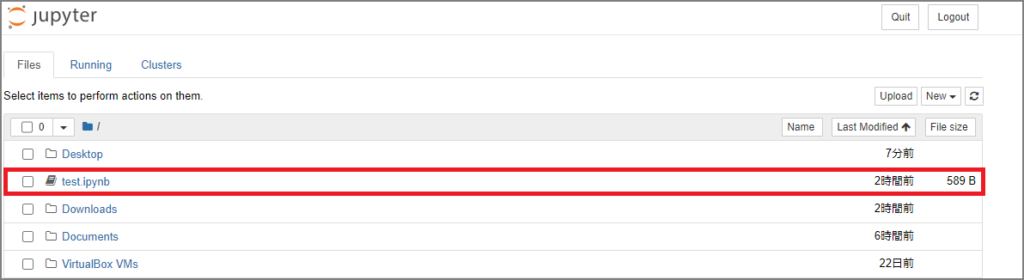
Cellと呼ばれる領域(Inではじまるセル)にPythonのプログラムを記述してShift + Enter キーで実行します。実行結果がOutに出力されます。
お疲れ様です。
今回はこれで以上になります。