Pythonでデータ読み書きを自動化する。
- fukutaku
- 2022年5月29日
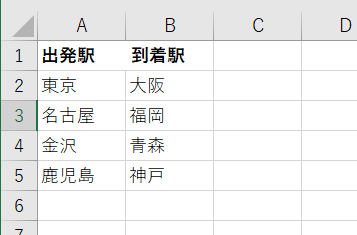
読み込み元データは下記Excelファイル
※下記は4行になりますが、行数が増減しても問題なく対応
できる自動化プログラムを制作します。
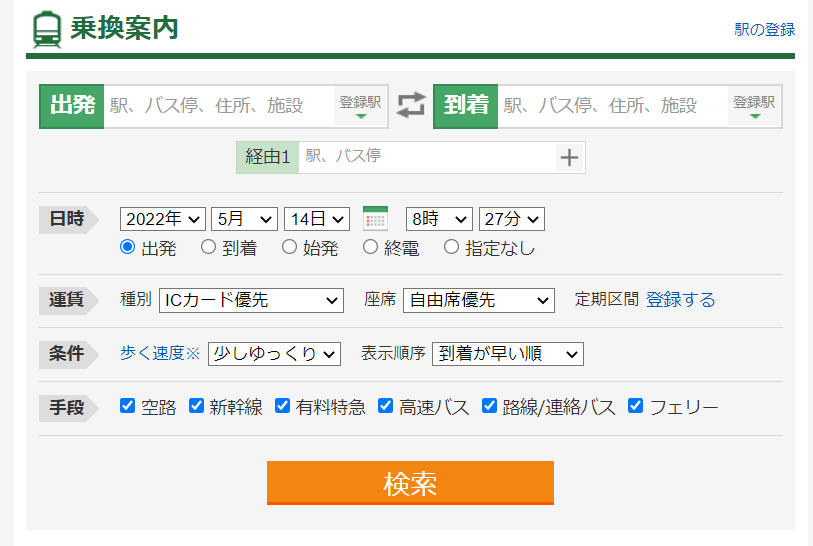
入力先は下記サイトになります。
以下手順を自動化します。
A列のデータを出発ボックス、B列データを到着ボックスに入力して
検索をクリックします。
検索後、最安値を取得してC列に書き込みます。
下記のように最安値が自動で書き込みされる処理を解説します。

もくじ
- Excelデータ読み込み
※A列、B列の2行目から読み込みしていきます。
繰り返し処理の解説も行います。 - データ入力
※読み込みしたExcelデータをweb上に入力します。 - クリックする
※webサイト上のボタンをクリックします。 - スクレイピング
※web上の任意のデータをスクレイピングします。 - 文字列の編集
※スクレイピングしたデータを任意の形にします。 - Excelへ書き込み
※スクレイピングしたデータをC列に書き込みます。
1.Excelデータ読み込み
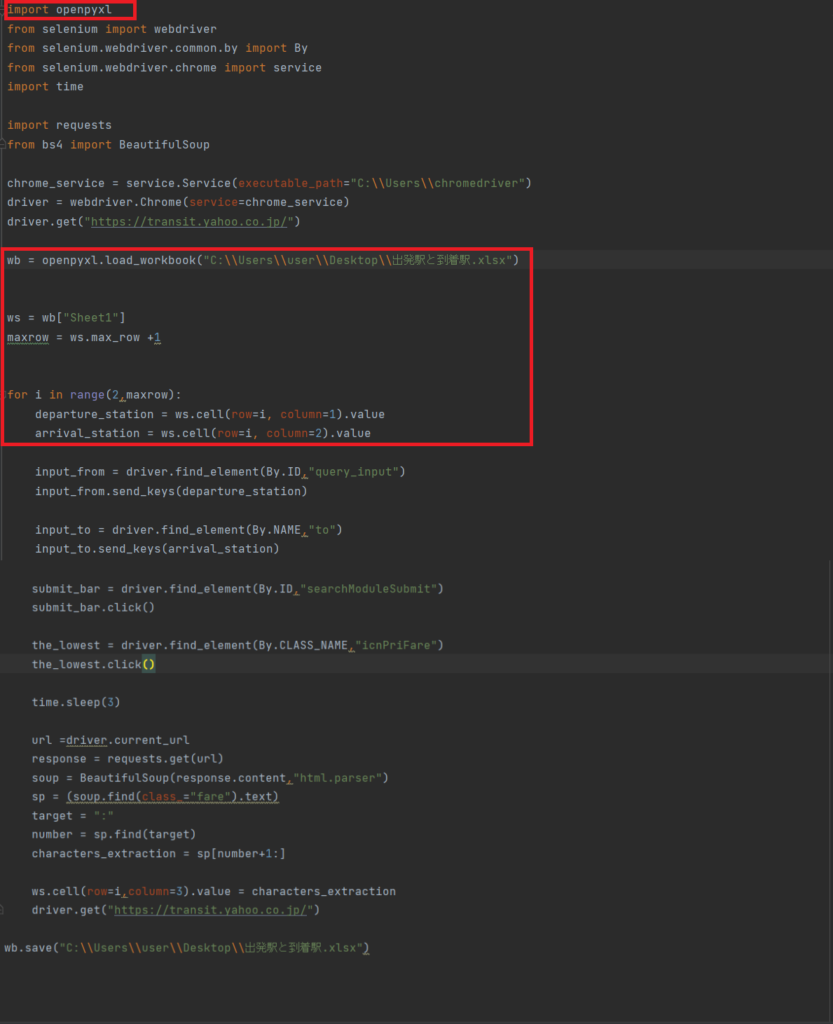
import openpyxl
→openpyxlライブラリをインポートします。
openpyxlはpython上でexcelを操作するためのライブラリになります。
※openpyxlは外部ライブラリとなりますので初めてご利用の場合コマンドプロ
ンプトからpip install openpyxl と入力してインストールが必要です。
wb = openpyxl.load_workbook(“C:\\Users\\user\\Desktop\\出発駅と到着駅.xlsx”)
→load_workbookメソッドでexcelファイルを読み込みます。
引数には読み込みしたいファイルのフルパスを記入します。
ファイルデータを変数:wbに格納します。
※pythonファイルとexcelファイルが同階層の場合、ファイル名のみでOK
です。
ws = wb[“Sheet1”]
→取得したファイルデータのsheet1のデータを変数:wsに格納します。
maxrow = ws.max_row +1
→max_rowにて最終行を取得します。
今回のExcelファイルですと5を取得します。
1をプラスして6とします。
※なぜ1をプラスするかというとrange()関数の仕様のためとなります。
後に解説します。
繰り返し処理
Excelファイルの行数分繰り返す処理を記述していきます。
for i in range(2,maxrow):
departure_station = ws.cell(row=i, column=1).value
arrival_station = ws.cell(row=i, column=2).value
→ここは少しややこしいので詳細に解説します。
セル値の取得は次のように記述します。ws.cell(row=2, column=1).value
rowは行、columnは列を表します。
row=2, column=1だとセルA2の値を取得しているわけです。
ws[“A2”].valueのように記述してもOKです。
どっちも”東京”が取得できます。
しかし今回はA2だけを取得したいわけではありません。
B2もそうですし、次はA3、B3と連続して取得したいわけです。
このような場合forループを用います。
for 変数 in 何かしらのデータ構造 のように記述します。
何かしらのデータ構造にはrange()関数がよく使われます。
書き方はrange(開始する値、終了する値)となります。
for count in range(1,4):の場合、
print(count) の実行結果は1,2,3となります。
そのため今回はfor i in range(2,maxrow):にて、maxrowは6が格納され
ているので変数:iに2,3,4,5と格納されていくことになります。
departure_station =ws.cell(row=i, column=1)
row = iとなっておりますので行が2,3,4,5とアップします。
※この辺は非常に重要ですので詳しく勉強するのであれば下記の書籍を参考
にすると良いと思います。
P62~P67に詳細が書かれています。

2.データ入力
ようやくデータ取得ができましたので今度はブラウザに入力します。
webブラウザを操作するため外部ライブラリseleniumをインストールします。
コマンドプロンプトからpip install seleniumと打ち込みます。

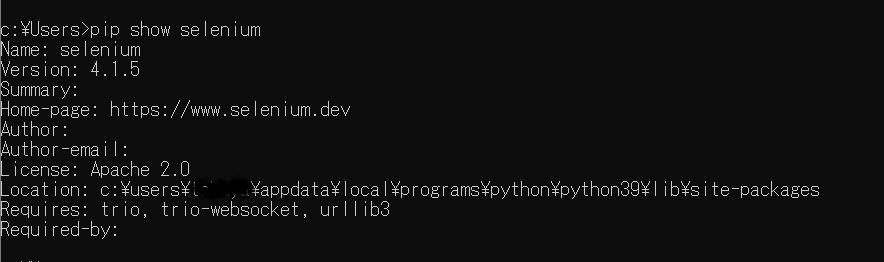
pip show seleniumと入力して下記のように表示されれば無事インストール完了です。
尚、Locationと表示されている箇所はインストールされている場所です。
それからWebDriverというものもインストールしなければなりません。
WebDriverにはバージョンがあり現在お使いのブラウザに合わせてインストールしなければなりません。
今回はchromeを自動操作対象としますのでchromeのバージョンを確認します。
chrome右上の ⁝ をクリック→設定→Chromeについてをクリックします。
下記のようにバージョンが記述されています。

バージョン確認後、下記サイトにアクセスしてドライバーをゲットします。
https://chromedriver.chromium.org/downloads
101に対応できる最新のドライバーをインストールします。
ご利用のクロムのバージョンにあわせて適切なドライバーをインストールしてください。

windowsなので下記を選択します。

ダウンロードが終わりましたらドライバーを取り出してどこか適当な場所に入れます。
私はusersの直下におきました。
C:\Users\chromedriver.exe
準備が長くなりましたがここから入力コードを記述します。
今回ターゲットとなるのは下記3か所になります。
この場所を指定する必要があります。
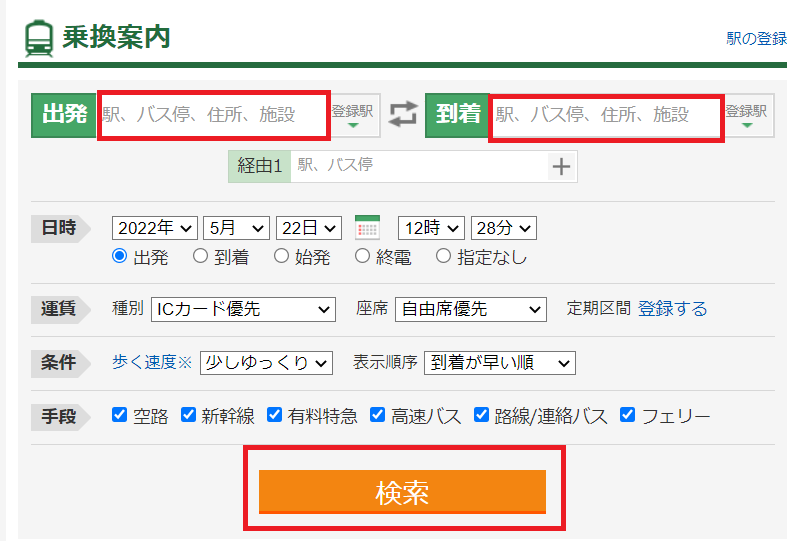
それでは場所を指定するにはタグを記述しなければなりません。
ここからHTMLのお話になります。
google chromeのデベロッパーツールを利用します。
Chromeでyahoo路線を開いて右クリック→検証を選択します。
すると下記のように表示されます。
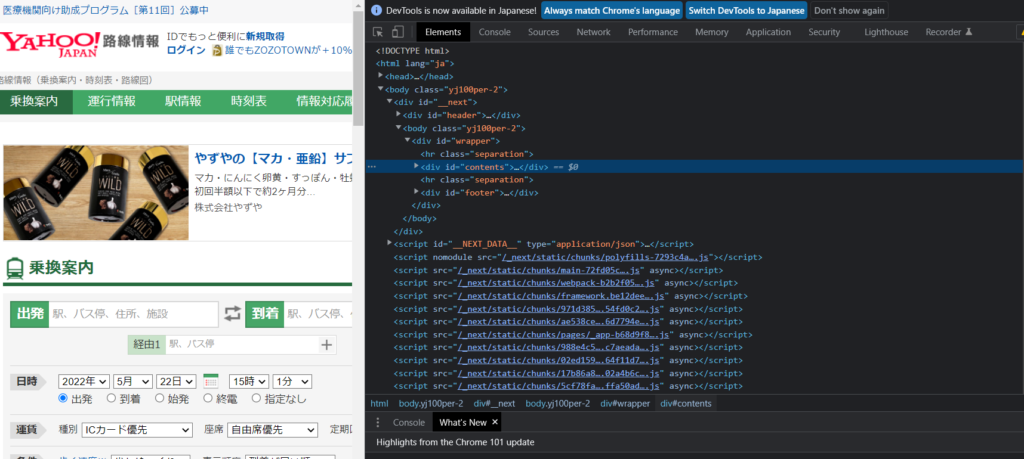
下記の赤枠のボタンをクリックします。
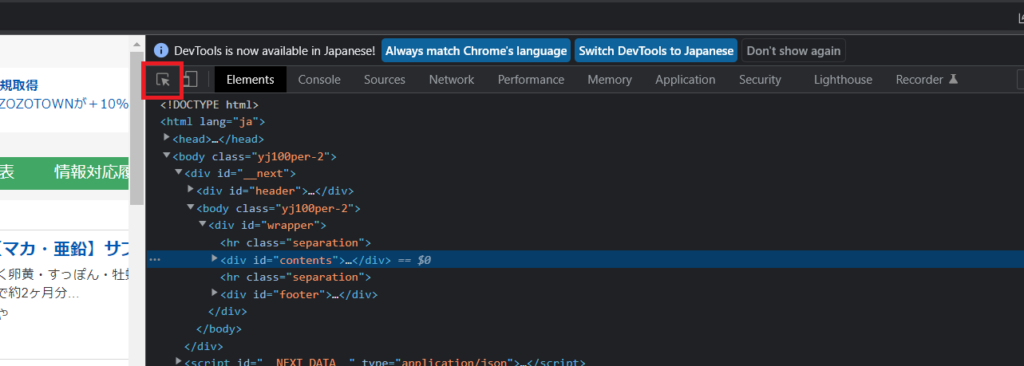
そして下記のように出発ボックスへカーソルを移動します。
色が変わります。
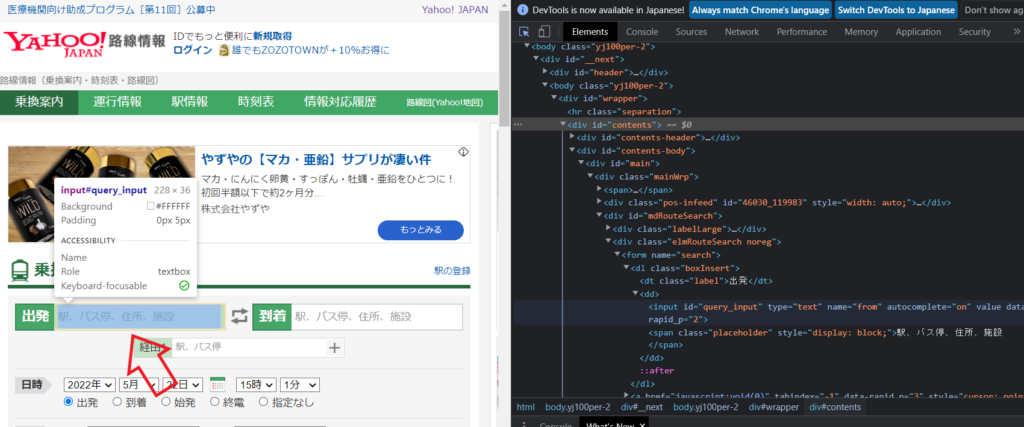
色が変わったところで左クリックをします。
すると下記のように青く色が変わった箇所が現れます。
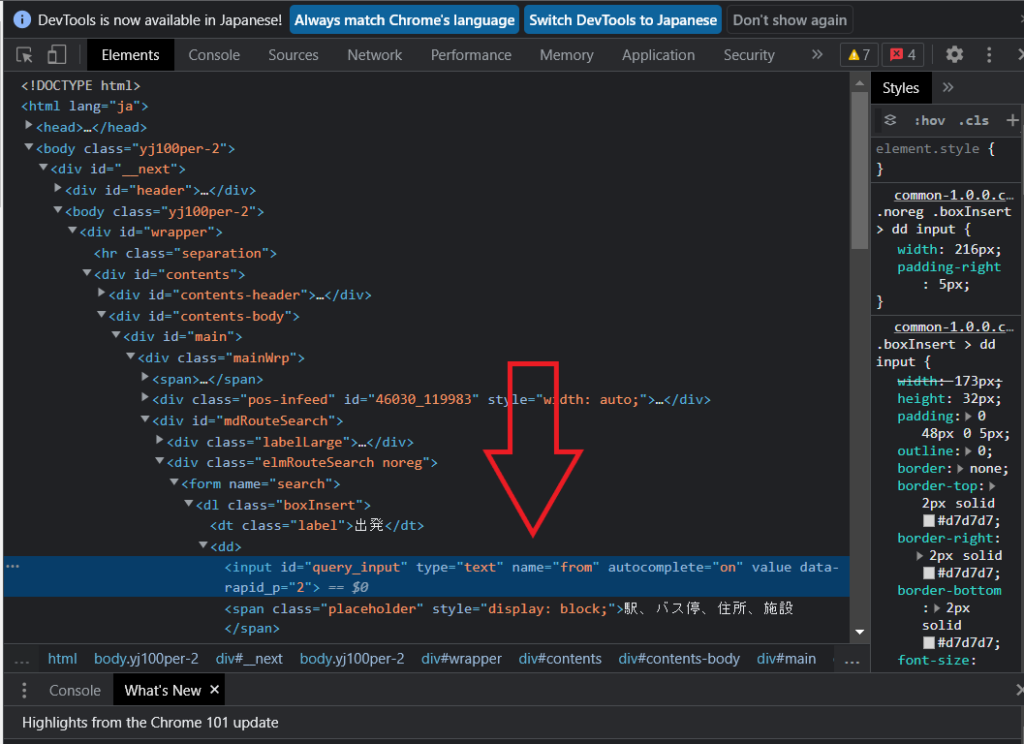
この薄く青色がかかった箇所が出発ボックスを構成している箇所になります!
そのためここの箇所の情報が出発ボックスを指定するのに必要になるわけです。
ズームしてみましょう。

HTMLを解説していると非常に長くなってしまうため簡単に説明します。
id やnameを属性といい、識別のために用います。
query_inputはidの属性値、fromはnameの属性値になります。
ようやくコード記述にたどり着きました。

from selenium import webdriver
→先ほどインストールして頂いた webdriverをインポートします。
from selenium.webdriver.common.by import By
→Byをインポートします。
(By.属性,属性値)のように記述して用いるために必要になります。
後ほど後述します。
from selenium.webdriver.chrome import service
→seleniumの4系ではドライバのパス指定においてserviceを利用する必要が
あります。
chrome_service =service.Service(executable_path=”C:\\Users\\chromedriver”)
driver = webdriver.Chrome(service=chrome_service)
→ドライバのパスを指定します。
driver.get(“https://transit.yahoo.co.jp/”)
→()内に指定したURLを表示します。
input_from = driver.find_element(By.ID,”query_input”)
→.find_element(By.属性,属性値)にて属性と属性値を指定して操作ターゲット箇
所を選択しています。
属性IDで属性値がquery_inputに一致する箇所をinput_fromに入力していま
す。
input_from.send_keys(departure_station)
→.send_keys(値)にて値を変数:input_fromに送ります。
(値)には先ほど出発駅が格納されているdeparture_stationとします。
input_to = driver.find_element(By.NAME,”to”)
→出発ボックスと同様、到着ボックスも.find_element(By.属性,属性値)にて属性
と属性値を指定して操作ターゲット箇所を選択しています。
異なるのは属性NAMEで属性値がtoに一致する箇所をinput_toに入力していま
す。
到着ボックスもID属性があるのですが属性値がquery_inputとなっており出発
ボックスと全く同じなのです!
もし同じ属性、属性値を指定しますと最初に見つかった箇所を指定してしまい
ますので到着駅名も出発ボックスに入力されてしまいます。
そのため到着ボックスの指定は属性値が出発ボックスと異なる属性NAMEを用
いました。
ちなみに出発ボックスのNAME属性値はfromです。
input_to.send_keys(arrival_station)
→.send_keys(値)にて値をinput_toに送ります。
(値)には先ほどの到着駅が格納されているarrival_stationとします。
3.クリックする
検索ボタンをクリックさせます。

この章でのコードは下記箇所

submit_bar = driver.find_element(By.ID,”searchModuleSubmit”)
→同様に.find_element(By.属性,属性値)にて属性と属性値を指定することで
ターゲット選択をします。
デベロッパーツールを用いて重複することがなさそうな属性IDを指定します。
指定箇所をsubmit_barに格納します。
submit_bar.click()
→.click()は左クリックを意味します。
これで検索ボタンがクリックされ、結果表示されている状態かと思います。

最安値を取得したいため料金の安い順をクリックします。
先ほどと同様にgoogle chromeのデベロッパーツールを利用します。
右クリック→検証を選択します。
料金の安い順を選択します。

料金の安い順のソースコードがわかったらコピーしましょう。
デベロッパーツール上で右クリック→Copy→Copy element
メモ帳に貼り付けます。
下記のように表示されました。
class属性が表示されております。
ここが目印になりそうです。

class属性を目印にして下記のように記述します。
the_lowest = driver.find_element(By.CLASS_NAME,”icnPriFare”)
the_lowest.click()
→同様に.find_element(By.属性,属性値)にて属性と属性値を指定することで
ターゲット選択をします。
※class属性はCLASS_NAMEと記述します。
→.click()は左クリックを意味します。
import time
time.sleep(3)
→timeライブラリを用いて待機時間を3秒ほどいれます。
料金の安い順をクリックしてから画面が切り替わるのに若干時間がかかるため
です。
画面が切り替わる前に次のスクレイピング処理が始まるのを避けます。
お使いのネット環境が悪い場合、5秒くらいにしても良いでしょう。
その場合、time.sleep(5)とします。
4.スクレイピング
いよいよスクレイピング(データ取得)になります。
これまでの記述で検索ボタンをクリックして料金の安い順まで押すことができるようになりました。
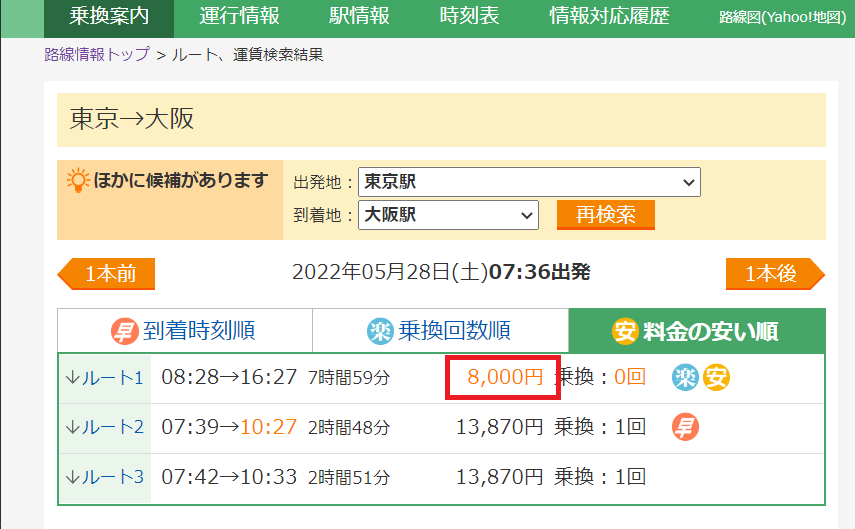
次は赤枠の8000円を取得したいと思います。
※最安値は時間帯で変動しますのでご了承ください。
またまたデベロッパーツールで解析します。
class=”fare”が見つかりました。
こちらを目印にしてコードを記入していきます。
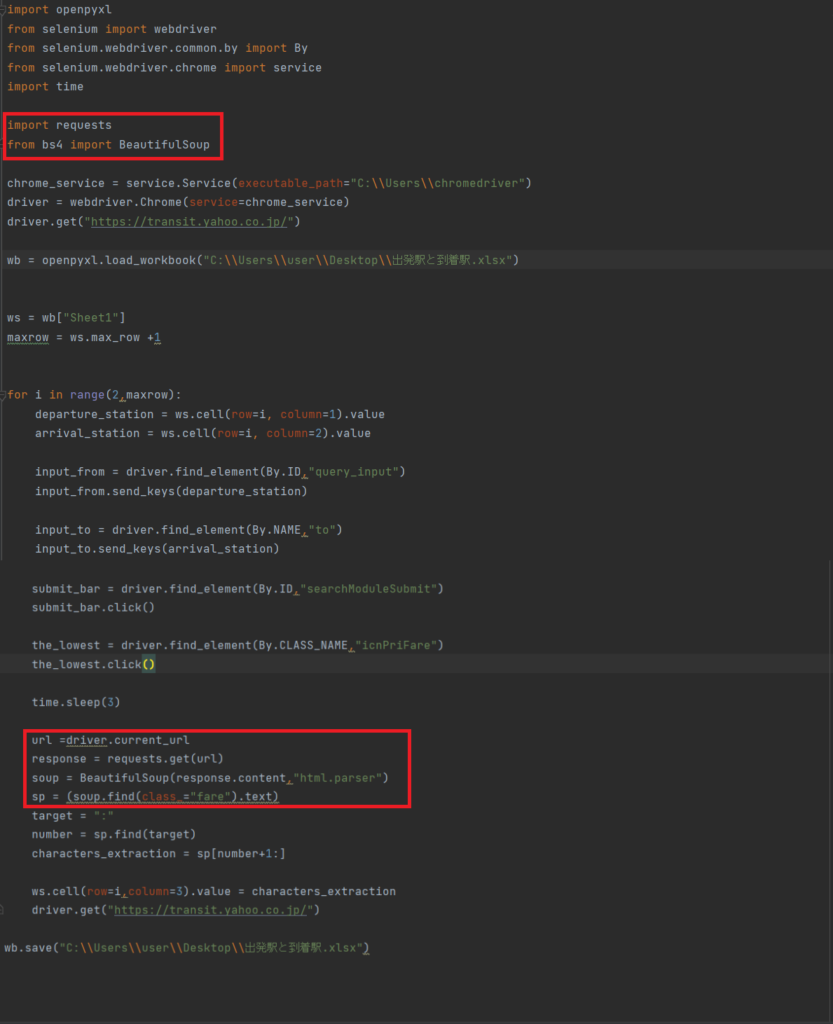
import requests
→requestsライブラリをインポートします。
インターネット接続用のライブラリになります。
外部ライブラリであるためコマンドプロンプトにてpip install requestsと入力
して事前にインストールしておきます。
from bs4 import BeautifulSoup
→BeautifulSoupライブラリをインポートします。
HTMLをスクレイピングしてくれるライブラリになります。
外部ライブラリであるためコマンドプロンプトにてpip install beautifulsoup4
と入力して事前にインストールしておきます。
url =driver.current_url
→.current_urlにて現在アクティブwindowのurlを取得して変数:urlに格納し
ます。
response = requests.get(url)
→requestsライブラリに.get(url)をつけることで
url※変数:urlに格納したurlを取得して、それを変数:responseに格納する
という意味です。
soup = BeautifulSoup(response.content,”html.parser”)
この1行でHTMLのデータ.contentをhtml.parserに渡すことを意味しています。
解析処理結果を変数:soupに入れます。
※html.parserはHTMLを解析してくれる処理になります。
sp = soup.find(class_=”fare”)
→デベロッパーツールで確認した結果class属性が設定されており、目印として
使えそうです。
属性class、属性値fare箇所を探して変数:spに格納します。
ここでspの中身を確認してみましょう。
下記のコードを追加します。
print(sp)
下記のように出力されました。

金額以外のタグ等も含まれています。
13,090だけ取り出したいので加工します。
先ほどのコードに.textと追加してテキストデータだけを取り出します。
sp = (soup.find(class_=”fare”).text)
print(sp)にて再度表示させます。
すると・・・
割とすっきりしました。

スクレイピングの基礎を学ぶなら下記をおすすめします。
非常に優しく書かれています。

5.文字列の編集
まだ不要な文字が入っています。
コロンより前が不要です。
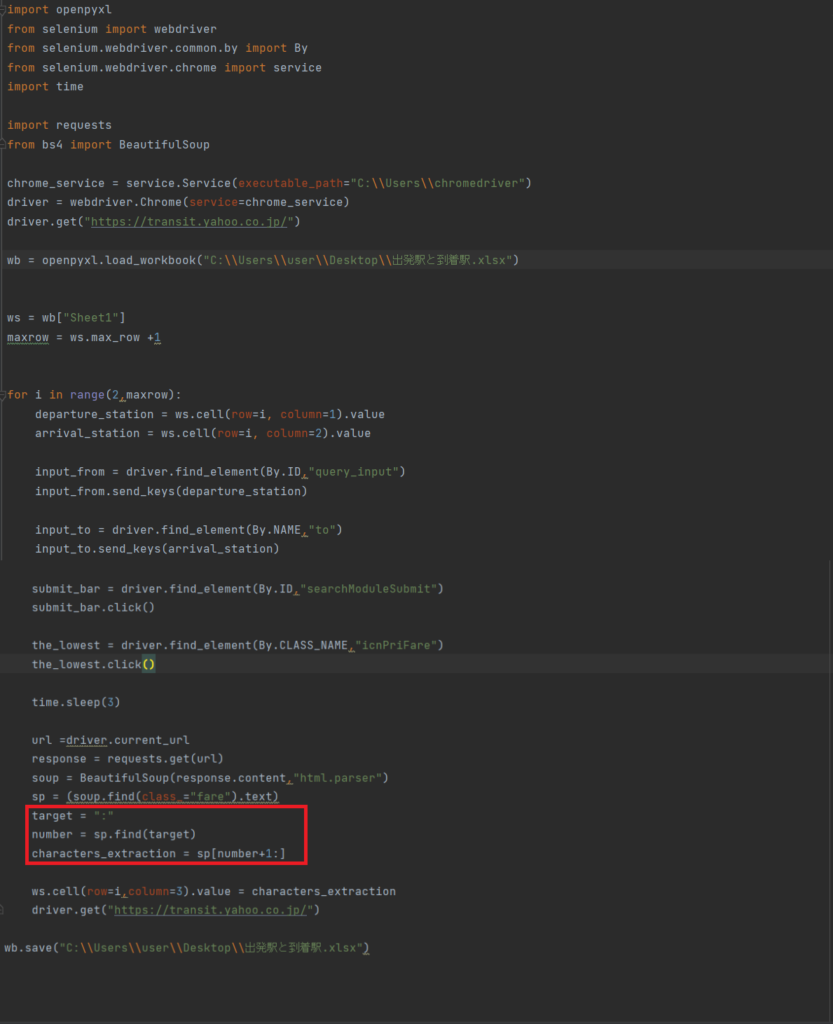
target = “:”
→変数:targetに:を格納します。
number = sp.find(target)
→コロンまでの文字数が取得できます。
0から数えますのでnunberには8が格納されることになります。
characters_extraction = sp[number+1:]
→コロンは不要ですので8に1プラスした9文字目から取得します。
これで13,090円のみ抽出できます。
6.Excelへ書き込み
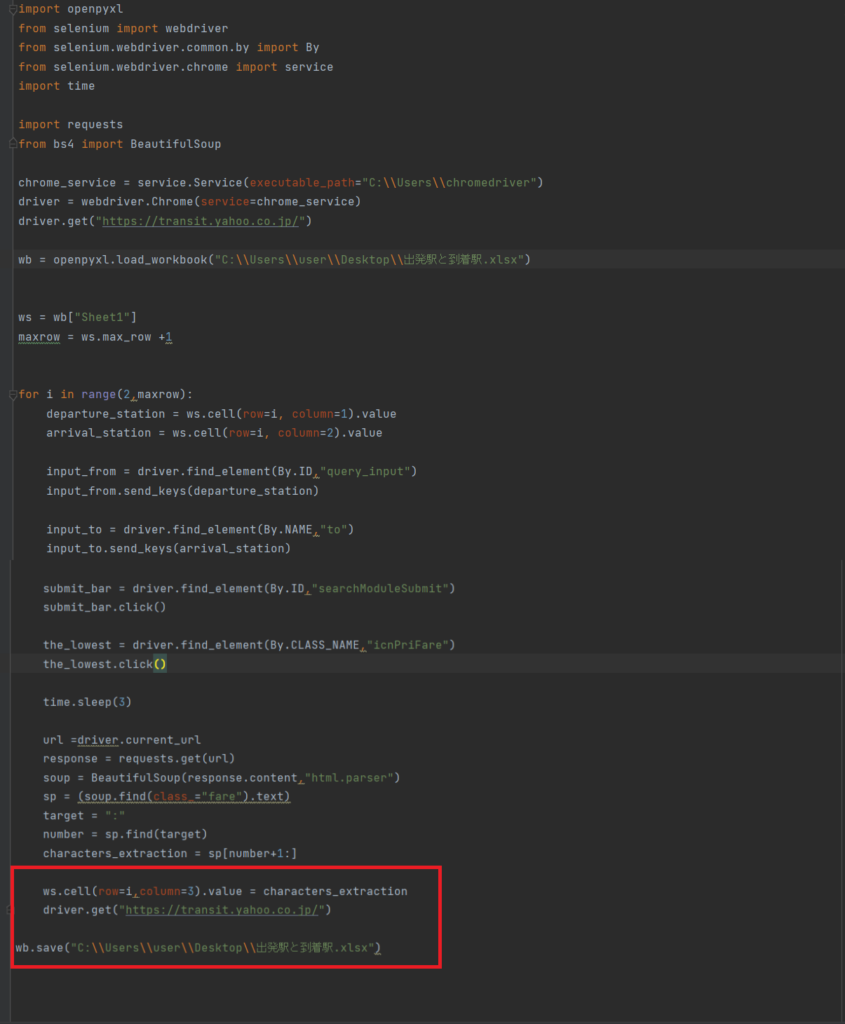
ws.cell(row=i, column=3).value = characters_extraction
→wsは対象シートが格納されています。
rowは行変数でカウントアップしていきます。
column=3はC列を意味しています。
指定セルにcharacters_extractionを書き込むということです。
driver.get(“https://transit.yahoo.co.jp/”)
→次の検索をしたいので最初の入力画面に戻る処理となります。
wb.save(“C:\\Users\\user\\Desktop\\出発駅と到着駅.xlsx”)
→最後に保存処理を入れます。
※記述中のpythonファイルとExcelが同じディレクトリであればフルパス記入
でなくてもOKです。
お疲れ様でした。
以上で完了です。
pythonを効率的、体系的に学ぶのであればプログラミングスクールも手かと思います。
貴重な時間の節約になります。
私も経験して、バグに悩む時間の短縮は非常にありがたかったですし、教材は期間が過ぎても閲覧できますのでずっと使えます。